AI修图全过程拆解:从点击到出图,你的照片经历了哪些AI处理
简单说:一张照片进入AI修图工具后,会依次经历场景分析→语义分割→任务匹配→模型推理→后处理→输出渲染六个步骤,全程耗时3-15秒。
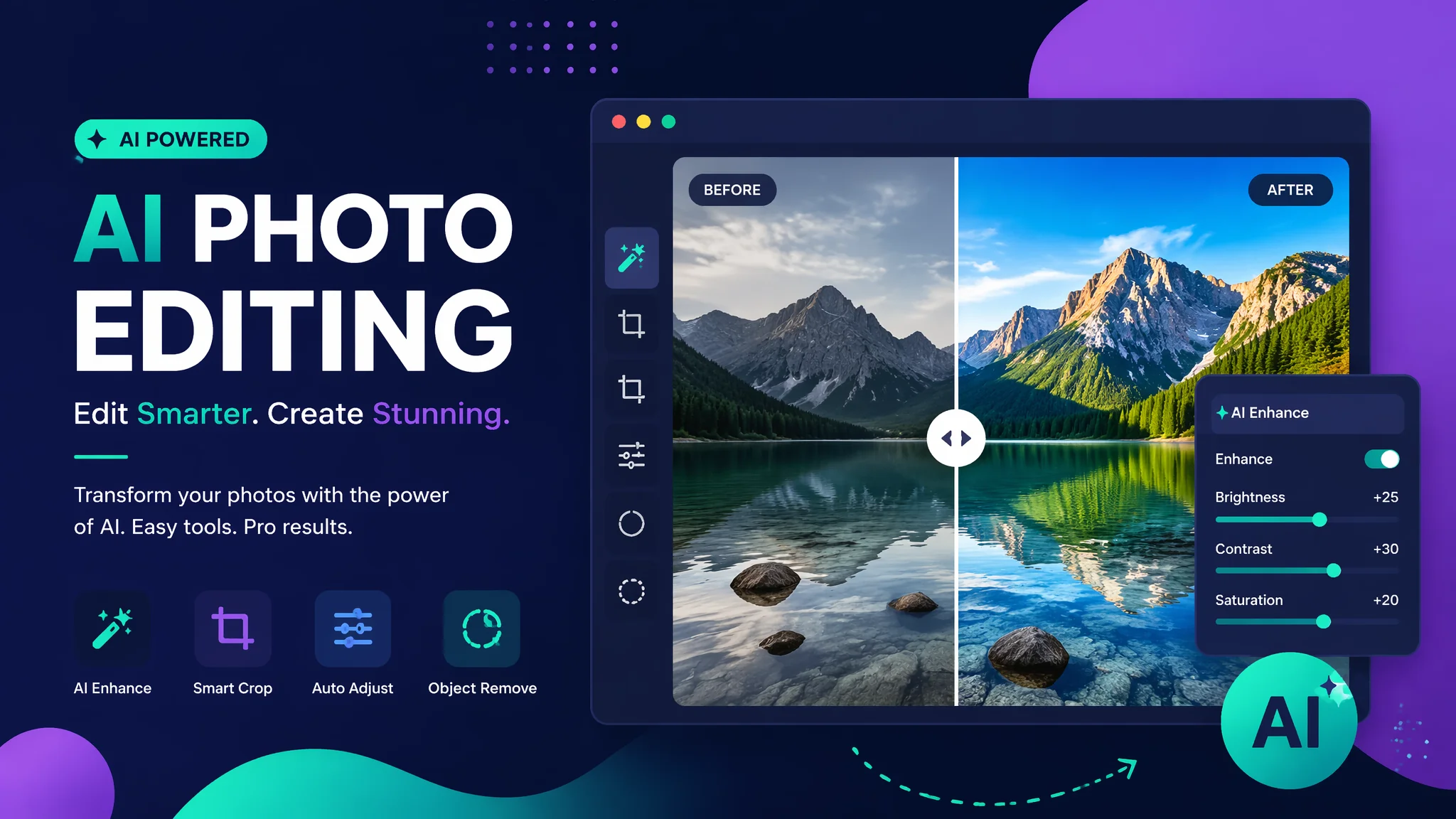
你点了一下"AI修图"按钮,一张照片在几秒内变得清晰、亮丽、肤色自然。这几秒钟里到底发生了什么?我花了几个月研究AI修图工具的底层流程,拆解了FlowPix和几款主流工具的完整处理链路。过程比我想象的复杂得多——一张2000万像素的照片在AI修图过程中被拆成数百个1080x1080的Patch分别处理,再无缝拼接回来。我试着用通俗语言把这个过程讲清楚。
第一步:场景分析与预处理
照片进入AI系统后,第一个动作不是修图,而是"看懂"这张照片——识别场景类型、检测主体、评估画质缺陷、确定处理策略。AI会同时运行多个分析模型:场景分类模型(判断这是人像/风景/文档/夜景/美食中的哪一类)、主体检测模型(找到画面中最重要的一到两个对象)、画质评估模型(计算清晰度分数、噪点水平、曝光状态、色彩偏差)。这个过程大约0.3-0.8秒。基于分析结果,AI决定后面的处理方案——人像就走美颜+肤色优化通道,风景就走色彩增强+天空优化通道,文档就走透视校正+文字增强通道。同一张照片如果同时有多个内容(比如人像+风景),AI会启用混合处理策略。
第二步:语义分割与区域划分
把照片分解成几十个语义区域是AI修图最关键的一步——天空、人脸、头发、皮肤、衣服、背景、前景……每个区域独立处理。语义分割模型(如SAM、UNet等)会给每个像素打上标签,区分出20-50个不同的语义区域。这一步的精度直接决定了后续修图质量。如果头发被误标为背景,修图时头发就会被当作背景一起模糊掉;如果天空被误标为白墙,AI做的天空增强就会翻车。主流工具在这一步的mIoU精度在85%-95%之间。FlowPix的分割引擎还针对亚洲场景做了专项训练——比如它能准确区分黑头发和暗背景,这是很多欧美工具在中国市场翻车的技术原因。
第三步:模型推理与图像生成
这是计算量最大的步骤——AI根据任务类型调度对应的深度学习模型,在GPU上做大量矩阵运算来生成处理后的像素。不同的修图任务调用不同的模型:超分辨率调用Real-ESRGAN类模型,降噪调用NAFNet类模型,美颜调用GPEN类模型,风格迁移调用ControlNet+Stable Diffusion。每张2000万像素的照片在推理时大约需要进行60-120万亿次浮点运算。这一步耗时最长,约占整个流程的60%-80%计算时间。为了加速,模型通常会被压缩量化(如FP16推理),同时使用CUDA或TensorRT优化。如果使用云端方案,这一步在数据中心的高端GPU(A100/H100)上完成;如果是端侧方案,跑在手机的NPU上。
第四步:后处理与质量检查
模型出图后不是直接给用户,还需要经过后处理环节:色彩空间转换、边缘平滑、噪点微调、输出格式编码。AI生成的原生输出可能会有细微的块状效应或边缘锯齿,后处理模块用传统图像处理方法做最后的打磨。这一步还会做质量检查——对比原图和结果图的PSNR和SSIM指标,如果发现严重退化(比如人脸被修成了另一个人),系统会自动调用保守策略重新处理。最后根据用户选择的输出格式(JPG/PNG/WebP)和参数(分辨率/质量/色彩空间)做编码。更多关于输出格式的内容可以看AI修图分享。
常见问题
AI修图过程需要联网吗?
云端方案需要,端侧方案不需要。大部分免费APP默认云端处理上传照片,部分工具提供离线模式。对隐私敏感的用户建议用本地处理方案。
为什么同一张照片每次AI修图结果略有不同?
生成式AI模型内部有随机性参数(如噪声种子),导致每次输出有微小的变异。大多数工具会固定种子以保证结果可复现,但部分创意功能保留随机性以产生多样效果。
AI修图会保存我的原图吗?
看具体工具的隐私政策。大部分工具会在处理后删除原图,但保留脱敏后的训练数据。建议阅读隐私条款,敏感照片优先选本地方案。
觉得有用的话分享给朋友吧。