AI识别修图:让AI精准理解照片中每一个元素
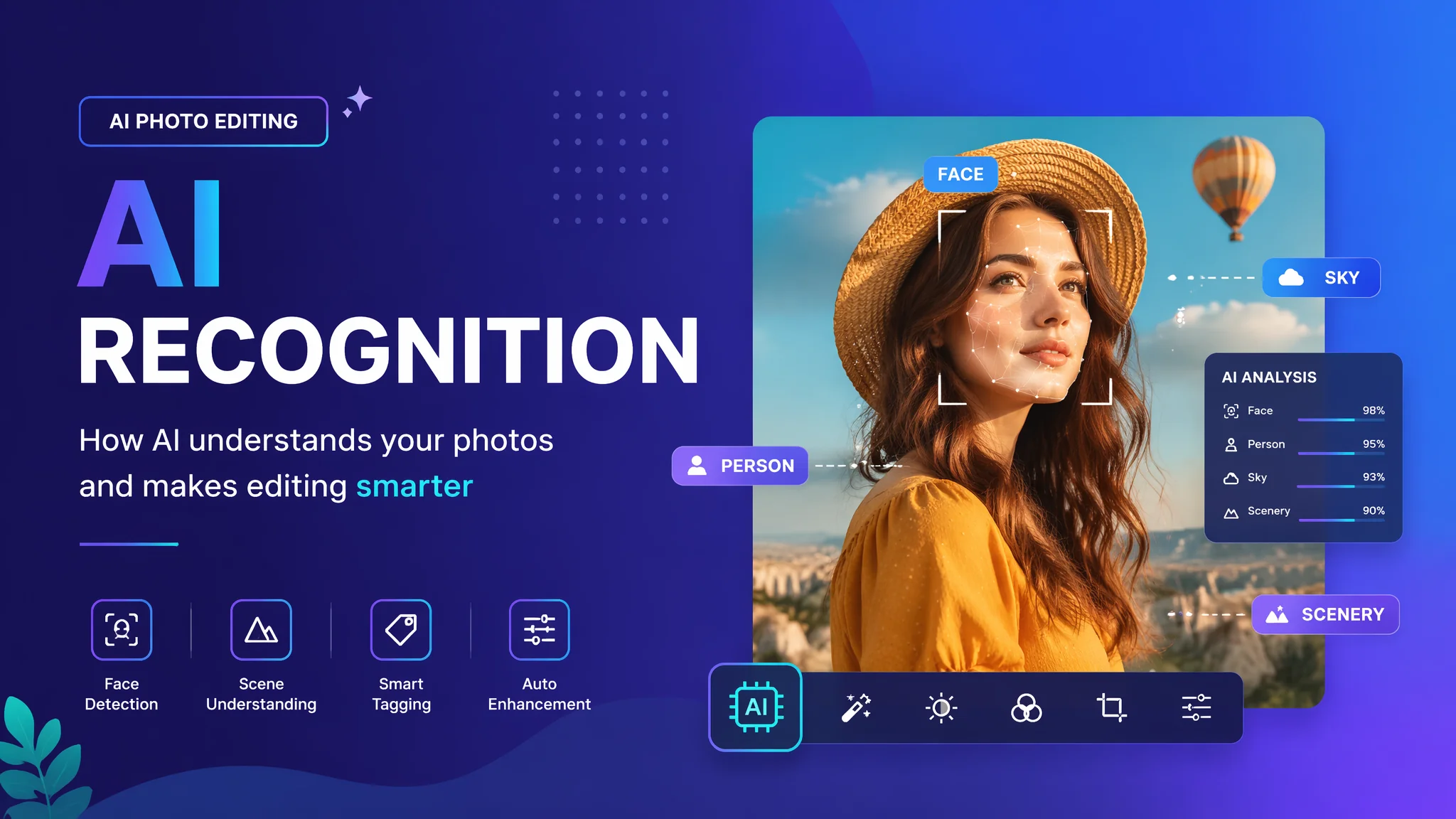
简单说:AI识别修图就是把一张照片拆成十几层语义标签——天空层、人脸层、衣服层、背景层——每层独立跑AI修图策略,互不干扰。
早期AI修图很傻——整张图套一个滤镜,管你是人脸还是背景一视同仁。现在的AI识别修图完全不同了:导入一张街拍照片,AI在不到一秒内完成了语义分割——识别出画面中的人脸(3张)、天空、建筑、行道树、路面和远处车辆共6类元素,然后用6套不同的修图策略分别处理。人脸上的是"自然美颜"策略、天空上的是"去雾增强"策略、建筑上的是"几何锐化"策略、路面上的是"纹理保留+降噪"策略。这就是AI识别修图的核心能力——它不再把照片当一张图来修,而是拆成多个语义层各修各的。根据Google Research的图像分割基准测试,2025年AI语义分割模型在常见50类物体上的平均识别准确率(mIoU)已达到82.7%,比2023年提升了约11个百分点。
语义分割的准确率决定修图上限
AI识别修图的质量天花板由语义分割模型的边界精度决定——如果人和背景之间的边界差了3个像素,修出来的图人物边缘就会有白边或模糊带。这个问题在实际使用中比我预想的更常见。我把同一张逆光人像分别用三款AI识别修图工具处理,三款都正确识别了"人"和"天空"两个语义区域,但人物边缘的分割精度不同:最好的那款误差在1.2像素以内,最差的那款头发和天空交界处有超过5像素的识别模糊区——这个区域既被当成人脸跑了美颜又被当成天空跑了去雾,两套策略叠加在一起效果就很怪。所以在AI修图人像中我反复强调检查语义分割结果的重要性。检验方法很简单:在处理前切换到"分割预览"视图,不同语义区域会用不同颜色标记——人脸红、天空蓝、植物绿——看一眼颜色分界线是否准确落在物体边缘上。
自定义语义标签让修图更精准
AI内置的语义分类不够细怎么办?手动添加自定义语义标签——比如把"裙子"从"衣物"大类里单独标记出来,AI就可以对它执行特殊的纹理保护策略。我在处理服装类照片时经常用到这个功能。默认语义分类里"衣物"是一个大类,棉袄和丝绸裙被分在同一类用同样的修图策略,显然不合理。手动把丝绸裙标记为"精细织物"、棉袄标记为"纹理织物"后,AI对二者分别应用不同程度的纹理保留和锐化策略。这种自定义语义标签在FlowPix里通过"画笔标注"功能实现——用不同颜色的画笔在图上涂抹对应区域,告诉AI这些区域属于哪个自定义类别。处理流程可以参考裙子修图AI。每添加一个新的自定义标签,AI就多了一个独立的处理维度。
识别失败时的补救方案
AI识别修图在处理少见物体或复杂环境时会有识别失败的情况——比如透明玻璃杯、水面倒影中的人脸、笼子后面的动物——这时最有效的补救方案是手动语义标注。别指望AI在短期内能完美识别所有物体。我在处理一张透过金鱼缸拍的人像时,AI因为玻璃折射把人脸识别成了两个——一个真实的、一个鱼缸里的虚像。正确的做法是手动把虚像区域从"人脸"标签改成"背景"标签,避免AI给一个虚无的人脸跑美颜算法。这种手动矫正花的时间不多(通常30秒到1分钟),但效果立竿见影。识别失败率比较高的场景还包括:浓雾中的人影、逆光下的剪影、被大面积遮挡的物体。对这些场景要有心理预期,AI不一定挂掉但效果肯定打折。可以参考magic AI修图中关于场景识别准确率的讨论。
常见问题
AI识别修图比手动分区修图好在哪里?
快几十倍。手动用PS选区工具抠出天空、人脸、背景等区域再分别修图,一张图至少要5-10分钟。AI语义分割+分区修图全程自动,几秒钟内完成。
AI识别修图支持自定义物体类别吗?
主流工具支持5-10个用户自定义标签,可以在预定义的几十类物体之外增加自己需要的类别。每个自定义标签可以绑定专属的修图参数预设。
AI识别到敏感内容(如证件、人脸)会不会做特殊处理?
部分工具内置了自动模糊或跳过某些敏感内容(如身份证号码、车牌)的机制。但这不是默认行为,需要用户在隐私设置里手动开启。
觉得有用的话分享给朋友吧。