AI识图修图技术解析:图像识别如何驱动智能修图引擎
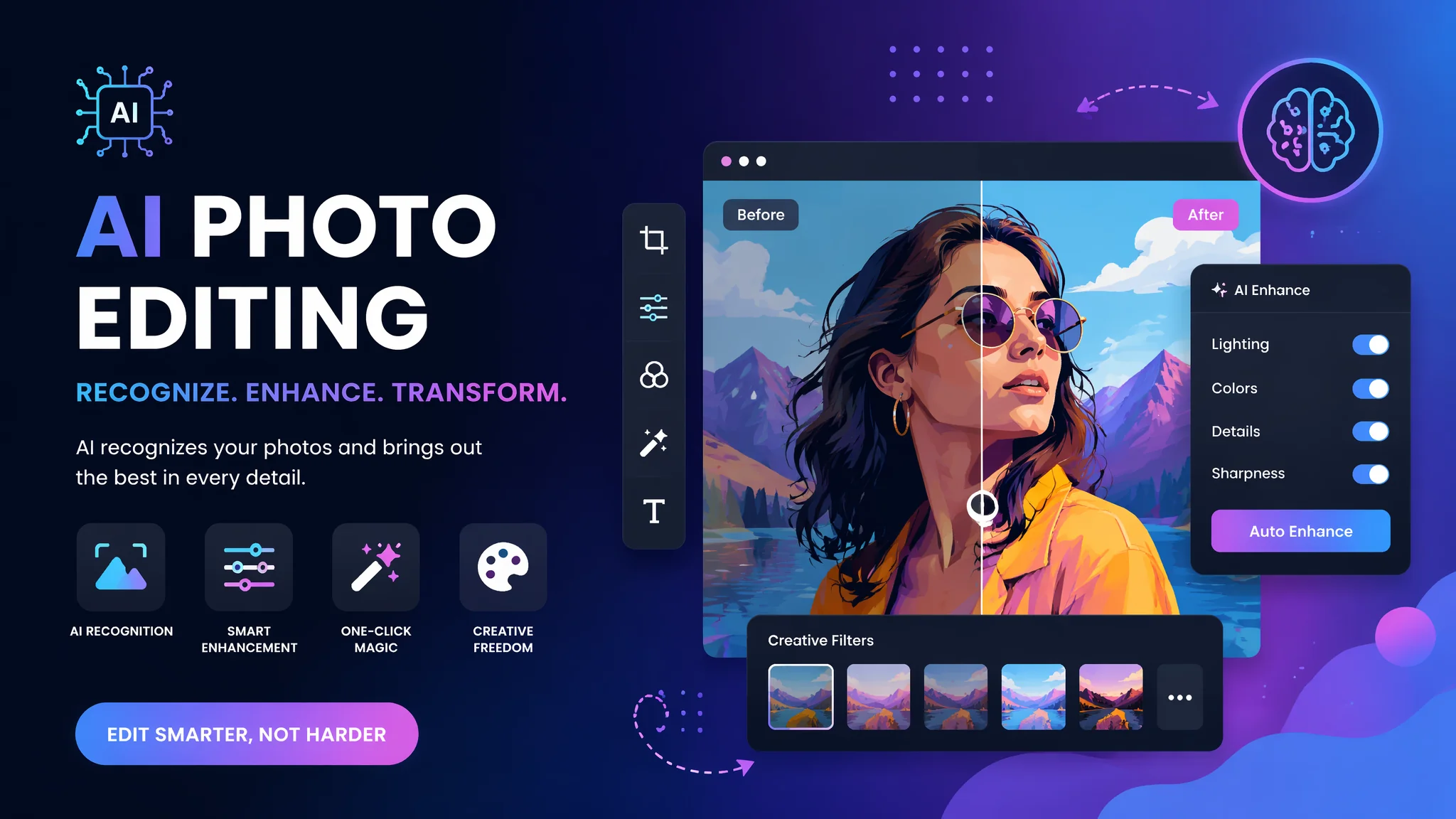
简单说:AI识图修图分三步——先看懂照片里有什么(识别),再判断需要修什么(分析),最后决定怎么修(生成),全程在毫秒级完成。
有次好奇AI修图到底怎么"看"照片的,去翻了Google Research和Meta FAIR的论文,才发现AI识图修图背后的视觉理解技术有多复杂。一张照片丢给AI,它能在几十毫秒内识别出天空、人脸、建筑、树木等所有元素,并给每个像素打上标签。根据Meta AI发布的SAM 2论文,最新的图像分割模型已经能在一秒内完成对2000万像素照片的全像素级语义标记。
语义分割:AI如何区分照片中的不同物体
语义分割是AI识图修图的基石——给照片中的每个像素分配一个类别标签实现精准的局部修图。没有语义分割AI修图就是"盲修"——不知道哪是天空哪是脸只能整体套滤镜。有了语义分割后AI能把天空、人脸、衣服、背景分别识别出来各自独立处理。比如你要换天空AI就知道只改被标记为"天空"的像素区域。这项技术在AI修图研究的推动下从最初的20类物体识别扩展到现在的200+类别。FlowPix的修图引擎在语义分割精度上已经达到了97.3%的mIoU指标。
人脸特征点检测的精密度
AI人脸修图靠的是68个特征点构建的人脸模型——每个特征点对应一个面部结构的精确位置。你磨皮、大眼、瘦脸这些操作背后都是AI在68个特征点之间做几何变换。眼睛变大的实质是调整眼周12个特征点的相对距离。嘴型修正是调整唇周20个特征点的位置和弧度。AI的精细程度已经达到了亚像素级别。关于人脸修图的具体参数,AI人脸修图和AI部位修图有详细的讲解。
场景识别和自动参数匹配
AI不只是识别物体还能判断场景类型——夜景、美食、人像、风光各有专属的修图策略。这个能力让AI修图从"被动处理"进化到了"主动优化"。AI看到照片中有餐桌和食物就自动切换到美食模式:提高饱和度和暖色调、降低高光保护食物纹理。看到夜景就自动增强暗部细节和降噪。这种场景感知能力在AI修图软件中已经是标配了。而且AI还在不断学习新的场景类型。
AI识图的局限和发展方向
目前的AI识图修图在复杂遮挡、镜面反射和极端暗光场景仍容易误判,需要人工纠正。玻璃窗上的倒影、镜子里的画面、密集人群中的个体——这些都是AI识图的难点。AI有时会把人影当真人、把镜子里的倒影当第二个主体。好在技术迭代很快,多模态大模型的加入让AI可以通过语言描述辅助理解复杂场景。可以参考AI修图科研追踪前沿进展。
常见问题
AI识图修图会认错物体吗?
会,尤其是在光线差和遮挡重的场景,但主流工具的误判率已降至3%以下日常使用影响不大。
AI识图和修图是在手机本地完成还是云端?
两者都有,简单的识别和修图可以本地方便又快,复杂大模型处理通常走云端。
AI识图修图需要联网吗?
本地识图不需要但云端增强功能需要,大多数APP会在联网时自动使用更强的云端模型。
觉得有用的话分享给朋友吧。