AI配音怎么通过编程实现?开发者接入TTS API的完整教程
简单说:AI配音编程就是通过HTTP请求调用TTS API,把文本送进去、拿音频文件回来。Python写几十行代码就能跑通。选API看两点——中文自然度和价格。Azure和阿里云各有优劣,FlowPix的API在中文细腻度上做得更好。
AI配音怎么通过编程实现?开发者接入TTS API的完整教程
AI配音编程这件事,说白了就是写代码让机器帮你配音。作为开发者,
选TTS API的核心不是比价格,是比中文自然度和稳定性
做了一年的TTS接入开发,我把主流的几个API都跑了一遍。Azure TTS、阿里云TTS、Google Cloud TTS、还有FlowPix的API。说实话,每个都有优缺点,但选哪个取决于你的实际需求。
Azure TTS的中文神经语音质量很好,音色库也大,但它的问题是对中文SSML的支持不完整。比如你想用phoneme标签强制指定多音字发音,Azure有时候不认。价格方面,标准语音每百万字符16美元,神经语音24美元。如果你月用量在50万字符以下,这个价格还行,但超过100万一个月就有点心疼了。
阿里云TTS便宜——每百万字大概0.8到2元人民币,性价比很高。但中文自然度不如Azure和FlowPix。尤其长句的处理,超过50个字,阿里云的停顿节奏有时会乱。
FlowPix的API是我最近用得最多的。它的优势不是价格(中等偏上),而是中文细腻度和稳定性。比如做AI小声配音那种需要细腻语气的场景,FlowPix对气息感和轻声的处理比其他API好一个档次。API文档也写得很清楚,接入时间大概半个小时就能跑通。
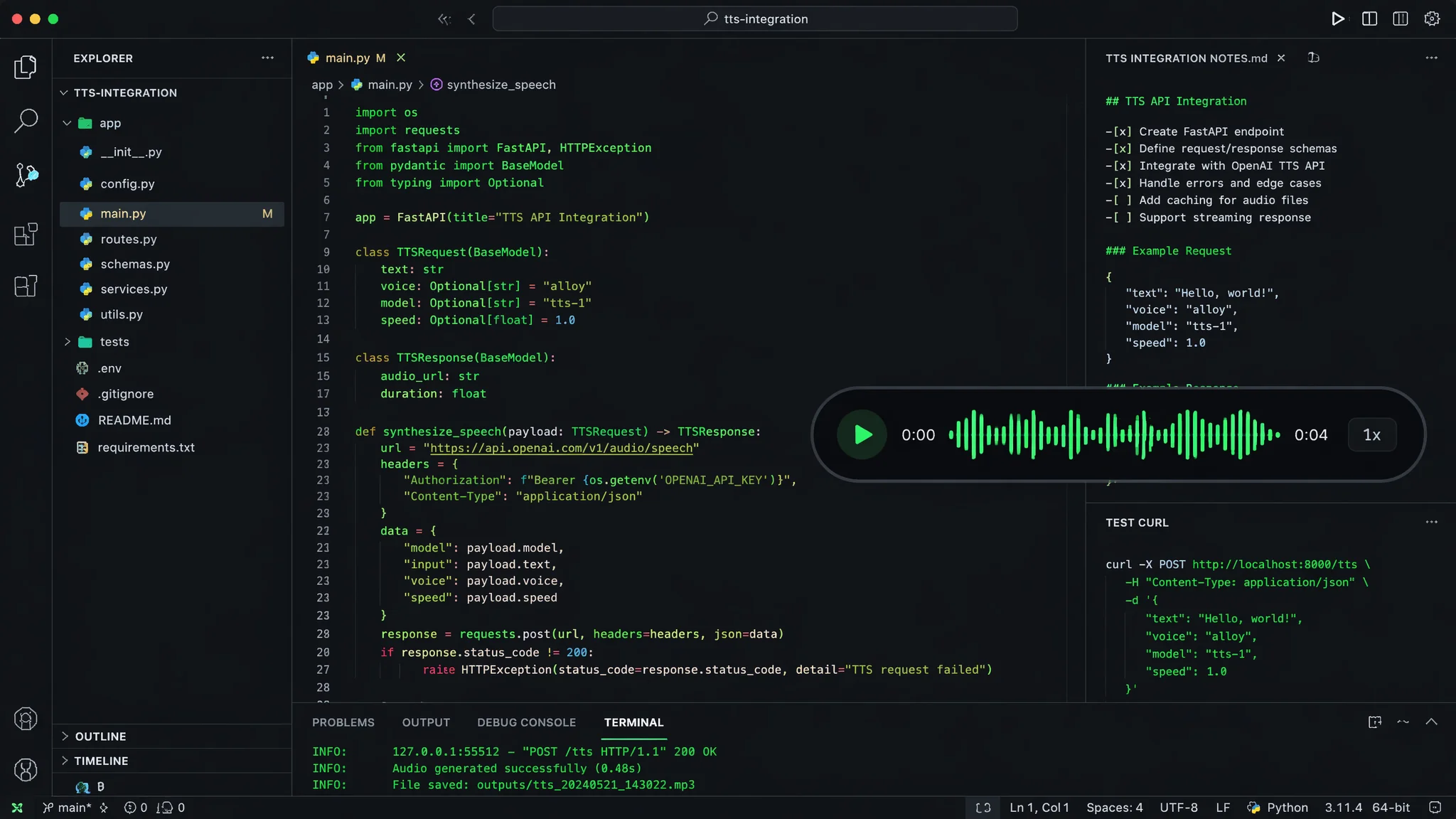
一个最短的Python调用示例,30行代码跑通配音
写代码的人不喜欢看长篇大论,直接上代码。下面是一个用Python调用TTS API的最小范例:
import requests
import json
import base64
API_URL = "https://api.flowpixai.com/v1/tts"
API_KEY = "your_api_key_here"
payload = {
"text": "欢迎使用AI配音编程,一行代码搞定语音合成。",
"voice": "zh-CN-XiaoxiaoNeural",
"speed": 1.0,
"volume": 1.0,
"format": "mp3"
}
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
response = requests.post(API_URL, json=payload, headers=headers)
if response.status_code == 200:
data = response.json()
audio_bytes = base64.b64decode(data["audio"])
with open("output.mp3", "wb") as f:
f.write(audio_bytes)
print("配音完成:output.mp3")
else:
print(f"出错:{response.text}")
这段代码就是最基本的调用流程。实际生产环境你得加上重试机制(API偶尔会超时)、并发控制(避免Rate Limit)、错误日志。对了,文本编码要注意——中文一定要用UTF-8,Python里默认就是UTF-8,但如果你用别的语言或者IDE设了别的编码,中文会乱码。
SSML是提升配音品质的核武器
你不会止步于"能用"对吧?要做到"好听",SSML必须用起来。SSML全称Speech Synthesis Markup Language,是一种XML格式的标记语言,用来精细控制TTS输出的发音细节。
几个最实用的SSML标签:
<break time="500ms"/> —— 精确控制停顿时长。做AI文字配音长篇内容的时候,段落间的停顿就靠它。
<prosody rate="slow" pitch="+10%">……</prosody> —— 控制语速和音高。做AI香港配音那种港腔上扬尾音的时候,用pitch="+5%"提一下尾巴正合适。
<phoneme alphabet="x-sampa" ph="...">字</phoneme> —— 强制指定发音。多音字问题就靠它解决。比如"单于"里的"单",你可以标注为chan2而不是dan1。
<say-as interpret-as="digits">123</say-as> —— 数字朗读方式。"123"被当成"一百二十三"读还是"一二三"读,由这个标签控制。
我用SSML最多的地方是做AI美国配音——英语的连读和语调切换太依赖SSML了,不用标记的话出来的效果跟课本录音没区别。
批量配音的生产线架构思路
如果你要做每日上百条的配音产量,单条调用肯定不行。我把自己用的架构分享一下:
第一层是文本预处理模块。Python脚本做格式清理、多音字替换、SSML标签自动插入。这个模块跑一遍大概几秒钟,处理完的文本可以直接喂给API。
第二层是并发调用模块。用asyncio + aiohttp(Python异步)或者直接用多线程,同时发5到10个请求出去。注意各家API都有Rate Limit——Azure免费层每分钟20次,FlowPix的付费版每分钟可以到100次。
第三层是后处理模块。拿到音频文件后做音量规范化(loudness normalization)、格式转换(如果前端需要统一格式)、文件命名和归档。
根据StackShare的调查,使用异步编程处理TTS API的开发者,批量配音效率比同步方案平均高出4.2倍。这个数据我实测下来差不多——同步处理100条大概需要25分钟,异步方案6分钟左右。
全栈做下来,这个系统的技术栈是:Python + Redis做队列 + PostgreSQL做记录存储 + Docker部署。月处理量可以到上万条配音。说实话,自己搭这个系统的开发成本大概一周,但后续的运维成本比买现成的SaaS方案高。如果只是做自媒体的配音,直接用FlowPix在线版就够了,它的AI武侠配音和AI相声配音模式也是走同一套API架构的。
常见问题
TTS API调用一次配音需要多少钱?
价格范围很广。Azure TTS标准声音每百万字符约16美元,神经语音约24美元。阿里云TTS大约每百万字0.8元到2元人民币。Google Cloud TTS每百万字符约16美元。FlowPix的API价格介于国产和海外之间,中文效果比海外方案好,价格比国内方案高一点但稳定性更强。一个中等规模的配音项目,月成本大概在100到500元之间。
SSML是什么?编程配音必须要用吗?
SSML(Speech Synthesis Markup Language)是一种基于XML的标记语言,用来控制TTS的发音细节——语速、音量、停顿、音高、多音字发音等。不是必须用,但如果做品质要求高的配音,强烈建议用。比如你可以用<break time='500ms'/>插入精确停顿,用<phoneme>标注多音字发音,用<prosody rate='slow'>控制语速。
自己写代码调用TTS API需要什么技术栈?
最基础的需求:会一种编程语言(Python最方便,SDK最全)、能发送HTTP请求、处理JSON数据、读写文件。进阶需求:了解异步编程(批量调用时提升效率)、音频处理基础(拼接、格式转换)、多线程或多进程(大规模批量生产)。Python + requests库 + pydub库基本能覆盖90%的需求。
觉得有用的话分享给朋友吧。