
AI克隆音色教程:怎么用AI完美复制一个人的声音特征
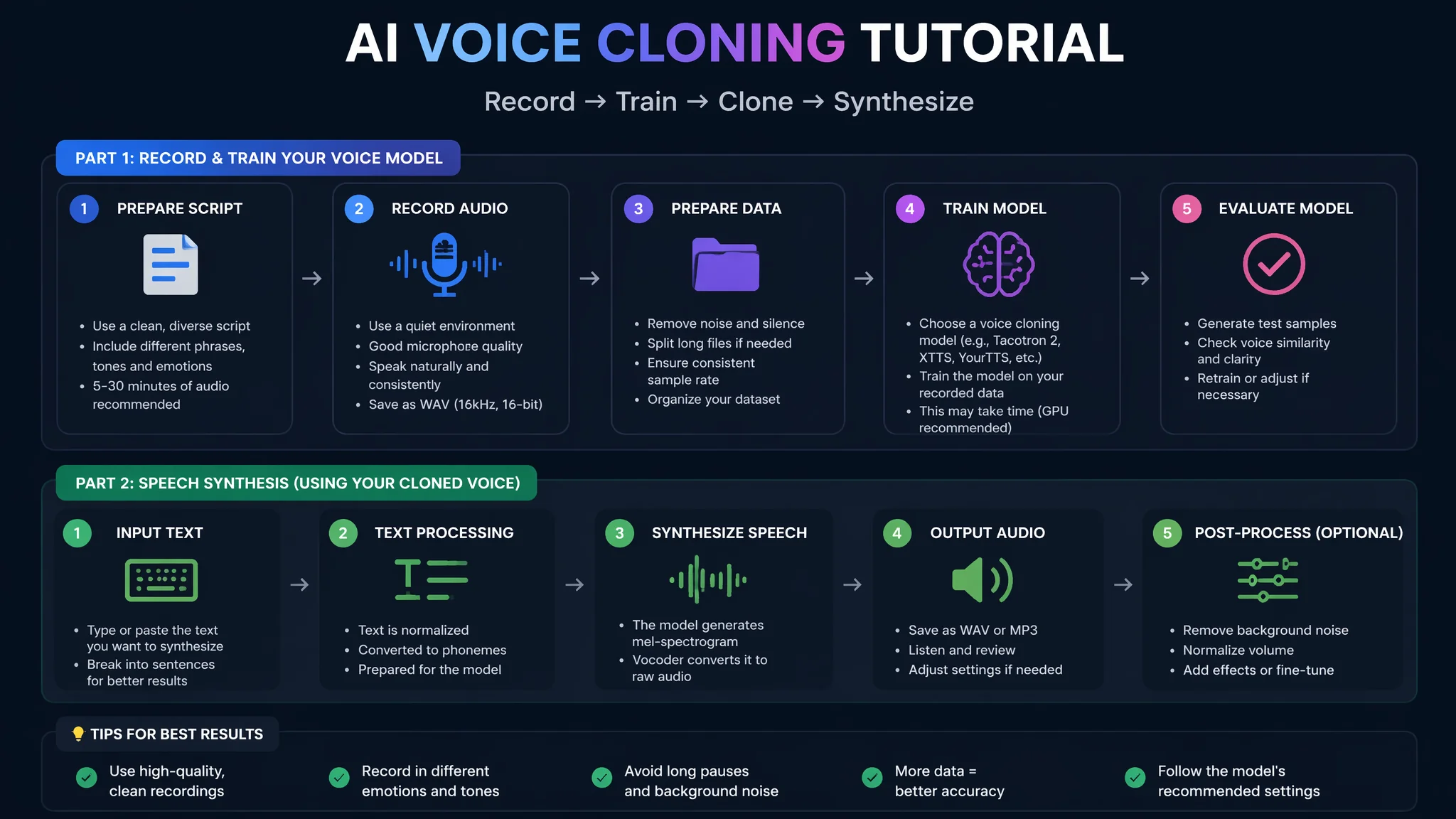
简单说:克隆一个人的声音只需四步——录一段目标音色30秒到2分钟的高质量音频→用Fish Audio或Coqui TTS提取声学特征(音高、音色、语速、发音习惯)→用这些特征微调预训练的语音模型→测试生成效果→不满意增加录音量重新训练。关键技巧:录音必须安静无噪音、语气自然不能太夸张、包含多样化内容(新闻+对话+数字提升泛化能力)。音频越长越像——30秒约80%相似度、2分钟约95%。
AI克隆音色教程:怎么用AI完美复制一个人的声音特征
10秒音频克隆出来的声音"有点像"——2分钟音频克隆出来的声音"就是这个人"。差距在哪?在数据量。这篇说清楚从录音到导出一个精准音色克隆模型的每一步。
四步完整克隆流程
第1步:高质量录音(最重要的一步)
录音要求:安静环境(无回音无空调噪音)、好麦克风(USB麦克风够了不需专业设备)、自然语气(不要紧张不要装腔作势)、多样化内容(正常聊天+朗读+数字日期+英文词汇)。最少30秒、推荐2分钟以上。录音质量直接决定克隆相似度的上限——这一步是"原材料",后面AI再强也弥补不了录音太差的缺陷。
第2步:特征提取+模型微调
录音导入Fish Audio或Coqui TTS→AI自动提取声学特征(基频、频谱包络、共振峰等)→把这些特征注入预训练语音模型做轻量微调。2分钟音频约微调几千个参数。微调时间取决于显卡——RTX 3060约15-30分钟、CPU约2-4小时。
第3步:测试和迭代
用未见过的文字测试克隆效果——对比原声和AI生成的声音。不满意的地方:增加录音量、调整训练参数、或者补充特定类型内容的录音(如发现AI读数字不自然就多录些带数字的句子)。通常第一轮80%→第二轮调优后90%+。
第4步:导出和使用
训练好的模型导出为.pt或.onnx文件→在配音软件中加载→输入任意文字AI用这个声音念出来。一个训练好的音色模型可以用在所有支持该格式的TTS工具中。
常见问题
克隆别人的声音违法吗?
克隆自己合法。克隆他人用于诈骗冒充非法。最安全:只克隆自己声音或获得书面授权。
声音克隆的技术门槛已经降到普通人也能操作的水平。花一个下午录好音→训练→你就能拥有一个"用自己声音念任何文字"的AI助手。
参考来源:Fish Audio