
AI配音模型训练教程:如何用自己的声音训练一个专属配音AI
简单说:想有一个"用你声音念任何文字的AI"?不需要用到ElevenLabs的商业服务——自己用VITS或Coqui TTS训练。流程:录30分钟到2小时高质量语音→转录成文字→用开源框架微调预训练模型→导出。需要NVIDIA显卡和Python基础。训练完成后就是只属于你的配音AI——完全本地、免费、不受次数限制。
AI配音模型训练教程:如何用自己的声音训练一个专属配音AI
我有个做自媒体的朋友,每期视频都要用自己的声音配音——手写脚本、对着麦克风念、不满意重录。一个10分钟视频的配音要录40分钟。我帮他训练了一个AI声音模型,之后他只需要打字——AI用他的声音念出来。
第一次听到AI用自己声音说出一段自己没说过的话——那种感觉,说实话挺奇妙的。
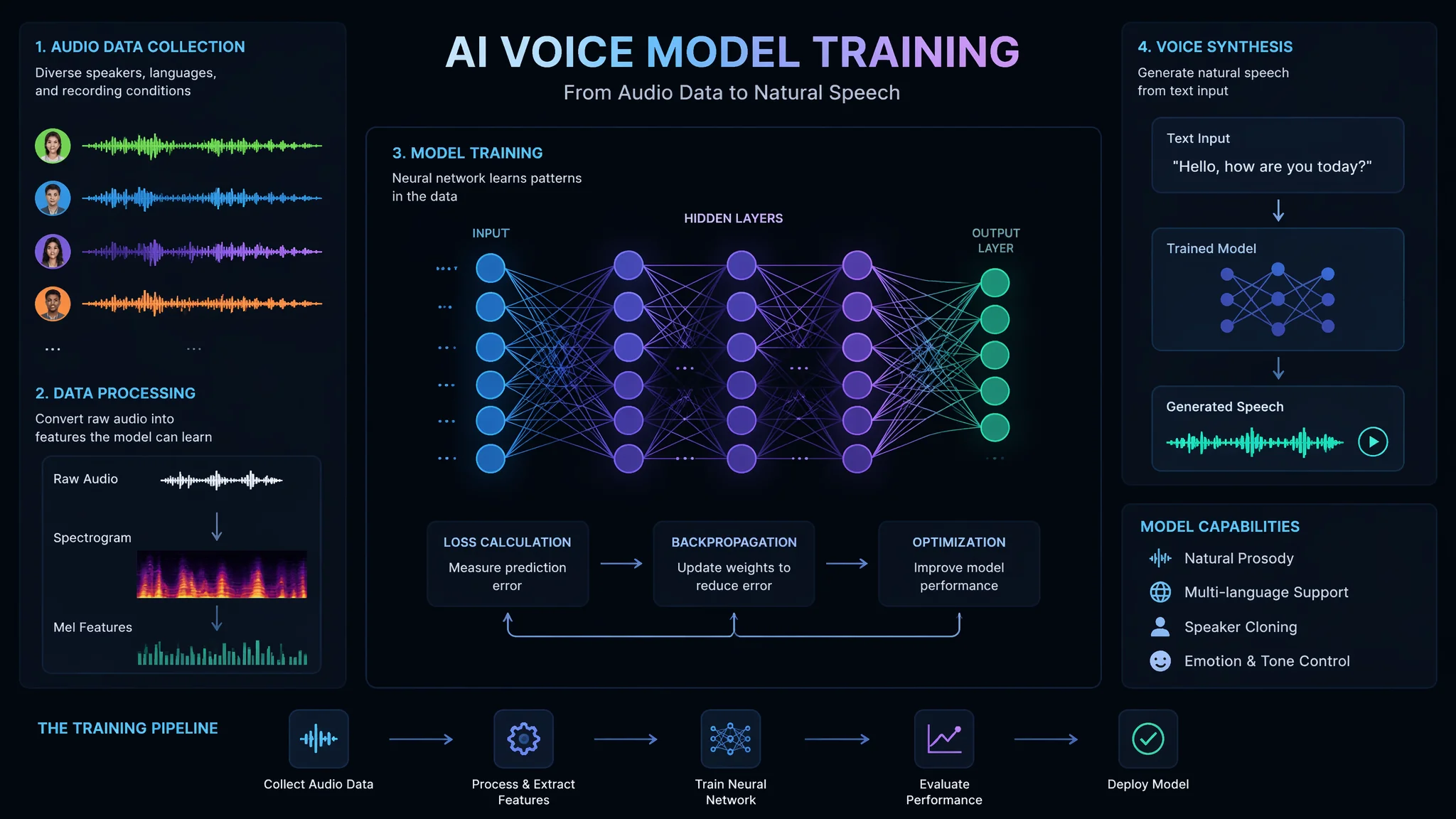
完整四步训练流程
第1步:录制训练音频
关键要求:安静环境(无回声无背景噪音)、较好麦克风(USB麦克风即可不需要专业录音棚设备)、自然朗读语气(不要像念课文那样平淡)、多样化内容(新闻+对话+朗读+数字都来点)。最少30分钟音频,推荐1-2小时。格式:16kHz或22kHz采样率、单声道、WAV格式。录音越长AI学得越像——1小时比30分钟的相似度多10%左右。
第2步:音频预处理和转录
用Whisper(OpenAI开源语音识别模型)把录音转成带时间戳的文字——这是训练数据的"标签"。然后需要手动校对转录文本——AI转的不一定是100%准。训练效果直接取决于文字标签的准确度——错一个词就可能影响最终效果。
第3步:选择训练框架并微调
两个推荐框架:Coqui TTS(易上手、文档全、支持200+语言、适合新手)和VITS(音质更好、中文优化更好、但配置更复杂)。下载预训练模型→挂载你自己的音频数据→开始微调训练。微调时间取决于音频量和显卡——1小时音频在RTX 3060上约8-12小时,在RTX 4090上约3-5小时。
第4步:测试和优化
训练完成后用未见过的文字测试输出——听听AI生成的声音和你原声的相似度。如果不满意:增加录音量重新训练、或者调整训练参数(学习率、训练轮数、batch size)。通常第一轮的相似度约80%,第二轮优化后可达90%左右。
常见问题
训练自己的AI声音需要多少录音?
最少30分钟推荐1-2小时。录音质量比数量重要——安静环境好麦克风自然语气。内容越多样化效果越好。
需要什么硬件?
NVIDIA显卡至少8GB显存(推荐12GB+)、32GB内存(推荐)、足够硬盘。不够可用Google Colab免费T4 GPU。
训练好的模型可以商用吗?
自己声音训练——完全可以商用。他人声音需明确书面许可。名人声音不建议(法律风险极高)。VITS/Coqui TTS开源协议允许商用。
训练一个自己的AI声音模型——前期确实要投入几个小时的录音和配置。但一旦训练好了,往后你只需要打字,AI帮你配音。这个"一次投入反复受益"的回报率,对需要经常配音的人来说极高。