微软ai配音数据参数详解:Azure TTS全部可调参数+最佳配置(2026版)
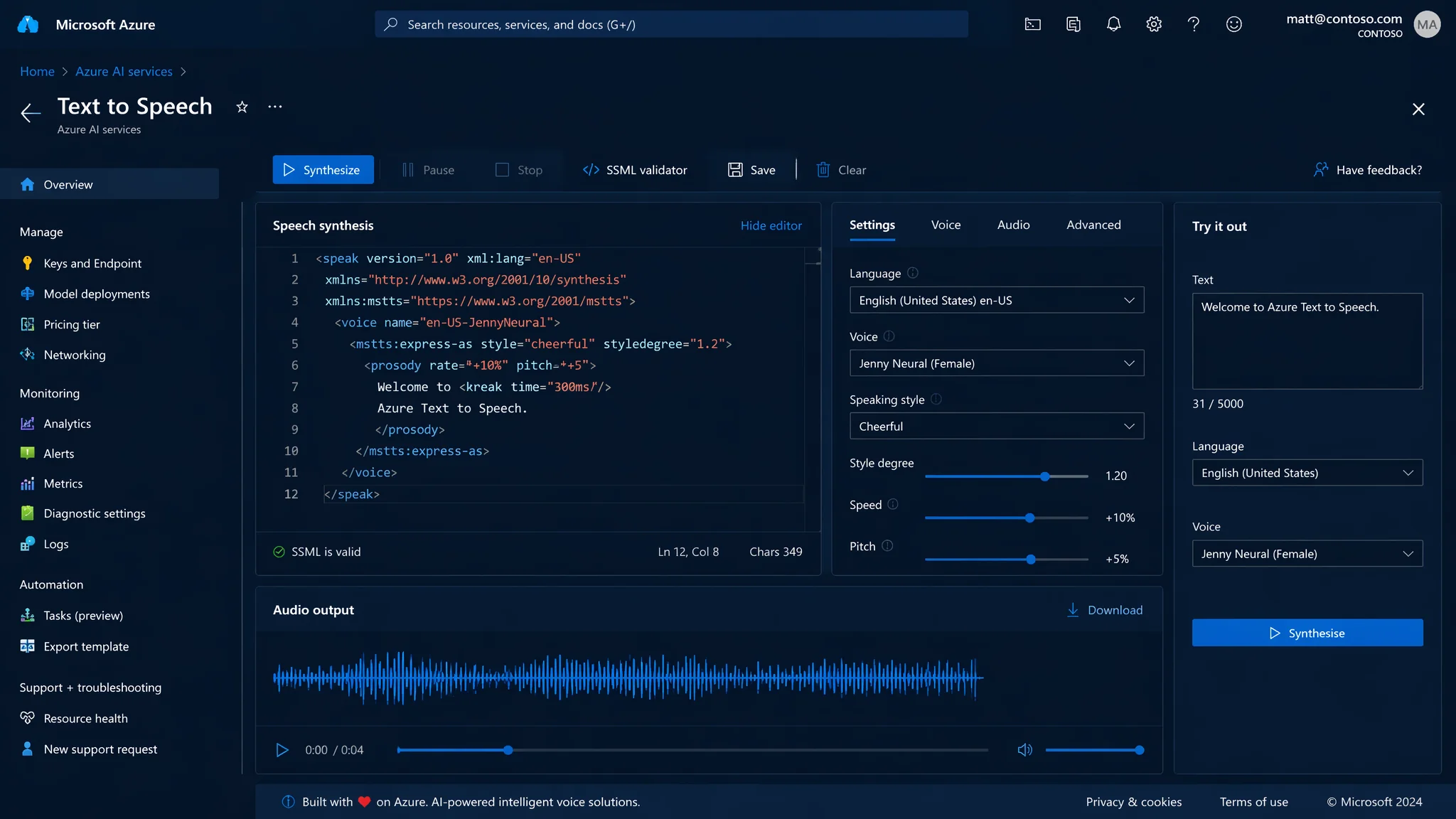
简单说:微软Azure TTS配音的核心可调参数就5个——语速(rate±50%)、音调(pitch±50Hz)、音量(volume±50%)、停顿(break ms)、发音(phoneme)。参数写在SSML标签里,调好了效果远超默认值。
微软ai配音数据参数详解:掌握Azure TTS的每个可调旋钮
用了快两年微软Azure的语音合成,说句实话——大部分人只用到了它10%的能力。打开默认参数、输入文本、点生成…然后就抱怨"微软的声音也就那样"。其实不是"也就那样",是微软ai配音数据参数你根本还没调。
这玩意儿像一台专业相机的全手动模式。默认Auto档拍出来平平无奇,但把光圈快门ISO都调对之后——完全是另一个级别。Azure的SSML参数体系就是这个"全手动模式",这篇文章帮你看懂每一个旋钮。
微软TTS参数体系全景:一张表看懂所有参数
Azure TTS的参数分为三层:最高频调节层(语速/音调/音量,每次都用)、中频调节层(停顿/发音,按需使用)、低频调节层(音效/背景/情感,特定场景使用)。下面这张表涵盖了所有主要SSML参数:
| 参数分类 | SSML标签 | 取值范围 | 影响效果 |
|---|---|---|---|
| 语速 | rate | -50% ~ +50% | 字与字之间的间隔长度 |
| 音调 | pitch | -50Hz ~ +50Hz | 声音高低(非响度) |
| 音量 | volume | -50% ~ +50% | 输出响度 |
| 停顿 | break | 0ms ~ 5000ms | 句中/句间静音时长 |
| 发音纠正 | phoneme | IPA音标 | 指定多音字读音 |
| 数字格式 | say-as | date/number/currency | 控制数字朗读方式 |
| 情感风格 | mstts:express-as | cheerful/sad/angry等 | 整体语气情调 |
| 背景音频 | audio | 音频URL | 混入背景音 |
核心参数一:语速(rate)——最影响听感的参数
语速是Azure TTS最常用的可调参数,用prosody标签的rate属性控制,默认"0%",范围-50%到+50%(实际有效区间约-30%到+30%,超出两端明显失真)。
不同内容的推荐语速:
- 新闻播报 → rate="-5%",偏稳偏庄重
- 纪录片解说 → rate="-10%",留足够时间让观众消化信息
- 短视频解说 → rate="+15%~+25%",信息密度高、节奏快
- 抖音带货 → rate="+20%~+30%",快节奏但不要说模糊
- 企业培训 → rate="0%~+5%",和真实语速接近
- 有声书 → rate="-5%~+5%",默认速度,偶尔加些变速丰富节奏
调语速的一个实操技巧:别只设一个全局rate,而是在段内动态变化。比如:
<prosody rate="+15%">大多数内容正常稍快</prosody> <prosody rate="-10%">重点结论放慢突出</prosody> <prosody rate="+25%">废话信息一带而过</prosody>
这种"变速朗读"是让AI配音不单调的最简单方法。但别变太频繁——一段30秒以内的内容,变速不要超过3次,不然听起来像卡带。
核心参数二:音调(pitch)——很多人和"音量"搞混
pitch控制声音频率高低,不是响度。单位是Hz或百分比,范围约-50Hz到+50Hz(或-20%到+20%)。+值让声音更尖细(偏女声/童声),-值让声音更低沉(偏男声/成熟)。
一段示例直接看区别:
<!-- 默认音调 --> <voice name="zh-CN-XiaoxiaoNeural">你好欢迎收听</voice> <!-- 偏高音调 —— 听起来更活泼、年轻 --> <prosody pitch="+15Hz">你好欢迎收听</prosody> <!-- 偏低调 —— 听起来更沉稳、专业 --> <prosody pitch="-10Hz">你好欢迎收听</prosody>
注意了:Azure的pitch参数默认是百分比(如"+10%")而非Hz。但如果你在SSML里写pitch="+10Hz",Azure也能识别——它会自动转换。不过文档建议用百分比,跨音色一致性更好。
还有个小坑:pitch只改变声音频率,不改变音色本身。你不能把男声调成女声——那需要换voice name。pitch只能在当前音色的声线范围内微调。
核心参数三:停顿(break)——区分AI配音和真人配音的关键
break标签插入静音停顿,分两种:break time="XXXms"(精确毫秒级)和break strength="weak/medium/strong"(语义级)。这是让AI配音从"念稿机器"变成"自然说话"最关键的参数。
很多AI配音听起来"机械感"的核心原因就是缺少自然停顿。真人说话在逗号处停200-400ms,在句号处停500-800ms,在段落之间停1-2秒。你不把这些停顿写进SSML,AI就会匀速念完——听起来像快进。
推荐停顿体系(直接拿去用):
| 标点/位置 | 停顿值 | SSML写法 |
|---|---|---|
| 逗号 | 200ms | <break time="200ms"/> |
| 句号 | 500ms | <break time="500ms"/> |
| 段落 | 1000ms | <break time="1000ms"/> |
| 重点前 | 300ms | <break time="300ms"/>重点内容 |
| 反问/设问后 | 600ms | <break time="600ms"/> |
说实话,手动给每句话加break标签很烦。建议写一个预处理脚本:自动在中文标点(,。!?)后面插入对应时长的break标签。
核心参数四:发音纠正(phoneme)——多音字救星
phoneme标签用于精确指定某个词的发音,使用IPA国际音标。当AI把"银行"读成"yinxing"而非"yinhang",或者把"长大"读成"changda"而非"zhangda"时,这个参数就是救星。
最常用的场景——纠正多音字:
<!-- "行长"被错误读成xingzhang,纠正为hangzhang --> <phoneme alphabet="ipa" ph="xaŋ˧˥ ʈʂaŋ˨˩˦">行长</phoneme> <!-- "音乐"被错误读成yinle,纠正为yinyue --> <phoneme alphabet="ipa" ph="in˥˥ ɥɛ˥˩">音乐</phoneme>
但讲真,phoneme用起来门槛不低——你得会IPA音标。对大多数用户,更实用的方式是:把多音字换成绝对不会读错的同音字替代。比如把"长大后"写成"掌大后",AI就绝对不会读错。生成完音频听众又看不到你写的原文。
实用SSML模板:直接复制改文案就行
我整理了两个实战模板,覆盖90%的使用场景:
短视频解说模板:
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:mstts="https://www.w3.org/2001/mstts"
xml:lang="zh-CN">
<voice name="zh-CN-YunxiNeural">
<prosody rate="+15%" pitch="+5%">
你的文案内容第一段
<break time="800ms"/>
你的文案内容第二段
<break time="500ms"/>
你的文案内容第三段
</prosody>
</voice>
</speak>
企业培训/纪录片模板:
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:mstts="https://www.w3.org/2001/mstts"
xml:lang="zh-CN">
<voice name="zh-CN-YunjianNeural">
<prosody rate="-5%" pitch="-5%">
<mstts:express-as style="newscast-formal">
你的文案内容
<break time="1000ms"/>
下一段内容
</mstts:express-as>
</prosody>
</voice>
</speak>
官方文档在 Microsoft Learn SSML参考,参数变化时以官方为准。
常见参数误区
误区1:rate调越大越好。错。rate超过+30%之后字间间隔短到人耳来不及分辨,反而影响理解。短视频追求快节奏没错,但信息传递效率比语速更重要。
误区2:所有音色用同一套参数。不同音色的"最佳参数"不一样。Yunxi(云希)的默认参数偏快偏亮,Xiaoxiao(晓晓)偏慢偏柔。同一套prosody设置放到不同voice上效果天差地别。
误区3:pitch大幅偏离默认。超出±20%之后声音会明显不自然。想大幅改变声音性别/年龄,正确做法是换voice name而不是调pitch。
常见问题
微软Azure TTS的语速参数调到多少最自然?
中文普通话推荐rate="0%"到"+10%"(默认到稍快),抖音风格短视频可调到"+20%"到"+30%"。低于"-20%"会像慢放,高于"+40%"开始失真。
Azure TTS的SSML标签有哪些是必用的?
必用:speak根标签、voice指定音色。常用:break控制停顿、prosody控制语速/音调/音量、phoneme纠正多音字。进阶:say-as处理数字/日期格式、audio插入背景音效。
微软AI配音参数和国内平台有什么区别?
Azure TTS的参数量级更多、可调粒度更细(支持百分位精确调节),但需要写SSML代码,上手门槛高。国内平台如魔音工坊把参数做成了可视化滑块,操作简单但调节精度不如Azure。
SSML参数调错了会怎样?
Azure会忽略无法解析的标签并继续生成(不会报错中断),但生成的音频可能不符合预期。建议用 Azure音频内容创作工具 的可视化界面先试参数,确认效果后再写SSML代码。
参数调好了,效果真的不一样。觉得有用分享给同样在折腾配音的朋友~ 还可以看 配音AI单是什么 和 AI语音配音软件对比。