
AI配音实时生成方案:文字输入即时出声音的最新技术进展
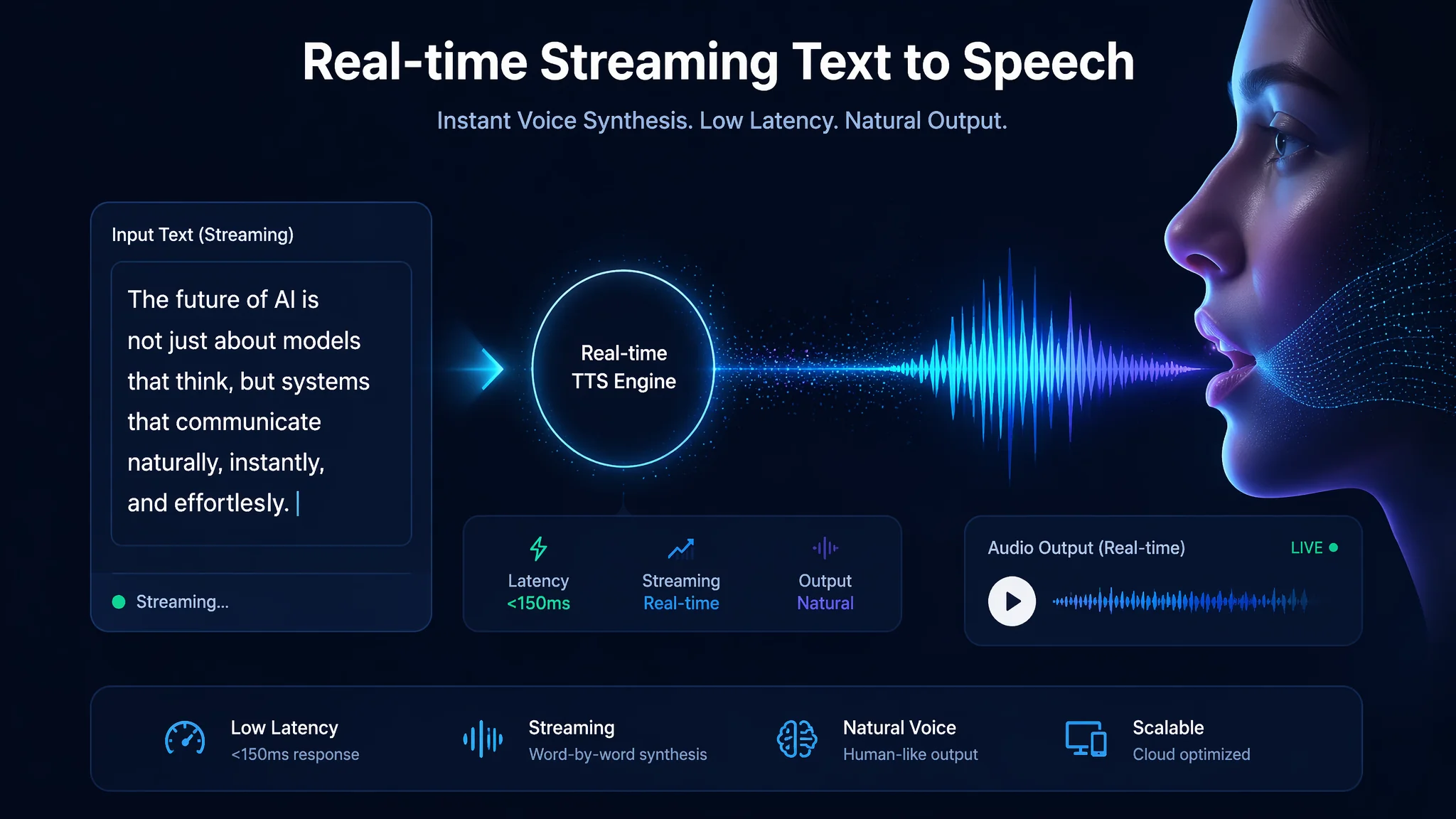
简单说:普通AI配音的流程是"输入文字→等5秒→下载→播放"——做不了实时对话。实时TTS(流式语音合成)能做到"第一个字输入完AI就开始念"——延迟约200-500ms几乎无感知。ElevenLabs的Streaming API、Azure的实时语音合成、Coqui TTS的流式模式都支持。做AI语音助手、实时翻译配音、AI客服——必须用实时TTS。
AI配音实时生成方案:文字输入即时出声音的最新技术进展
你和ChatGPT打字对话——GPT回复文字是"一个字一个字往外蹦"的流式输出。TTS也可以这样——实时语音合成把AI生成的每个词立刻变成声音播出来,不用等全文生成完。
实时TTS三大方案
1. ElevenLabs Streaming API——首字延迟约200-500ms
ElevenLabs的Streaming模式——AI模型接收文字的同时就开始生成音频片段并传回客户端。客户端收到音频片段立刻播放——不等完整的消息生成完。体验上——你打完一句话AI几乎同步开始说话。
2. Azure实时语音合成——企业级稳定
Azure的实时TTS支持WebSocket连接——建立连接后持续发送文字持续收到音频、零断开。对做AI语音客服的企业来说——这是最适合云部署的方案。
3. Coqui TTS本地流式——完全离线实时
在本地部署Coqui TTS并开启流式模式——延迟只有100-300ms(取决于显卡)。完全本地处理——不上传数据、不依赖网络质量。做嵌入式设备和隐私敏感的AI语音产品首选。
常见问题
实时TTS的延迟是多少?
ElevenLabs约200-500ms、Azure约300-800ms、Coqui TTS本地约100-300ms。普通完整生成TTS约2-10秒。实时TTS把这几秒几乎消除。
做AI语音产品——如果用户要等超过1秒才有声音——体验已经差了。实时TTS就是为这个场景而生的。关注FlowPix看更多前沿AI技术。
参考来源:ElevenLabs | Azure