
语音合成工具对比:TTS引擎的技术流派和各自的优缺点
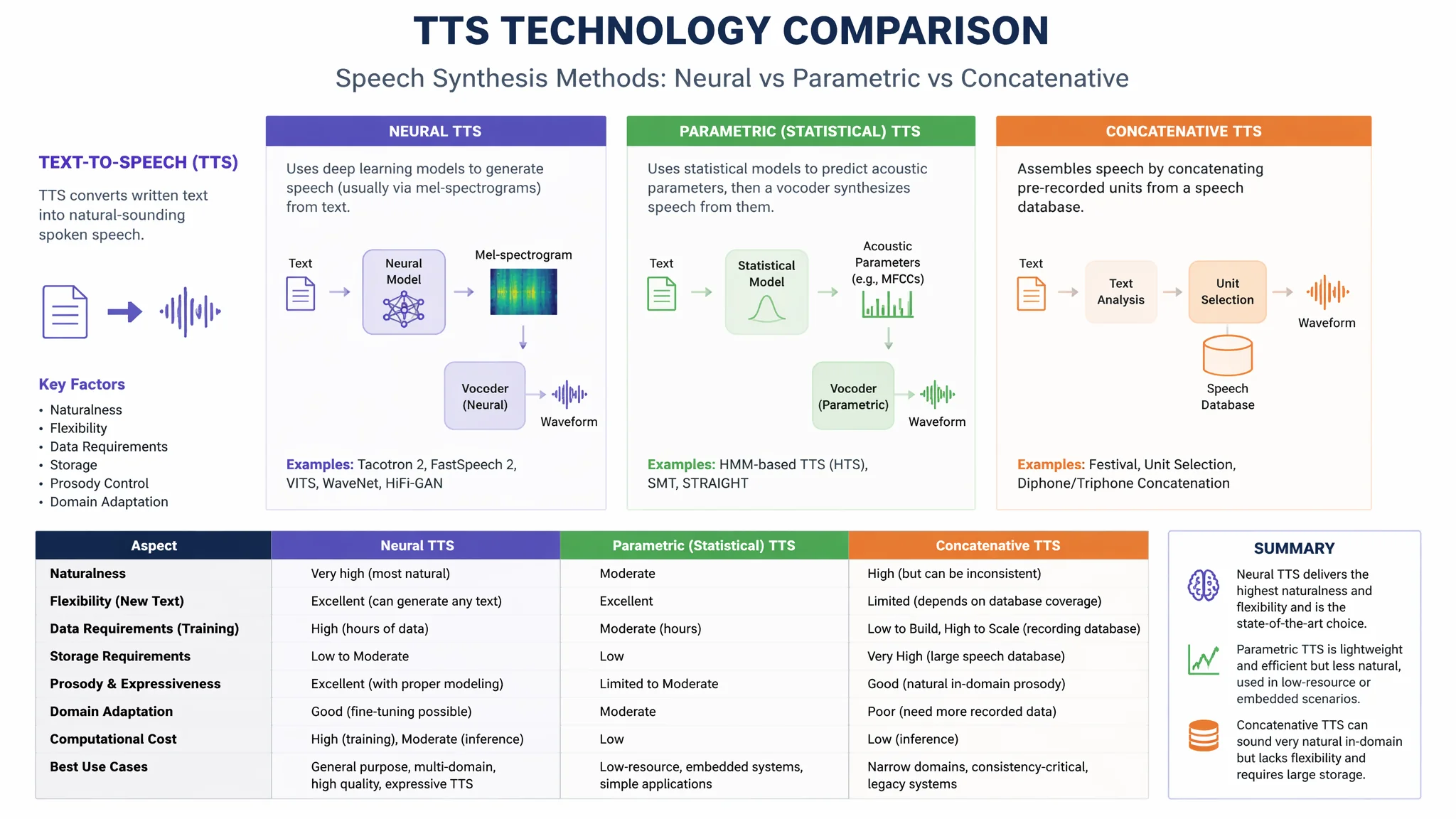
简单说:语音合成(TTS)经历了三代技术——参数式(最早——速度快但全是机械音)、拼接式(从真人录音中拼词——音质好但需要海量录音且不灵活)、神经网络式(目前主流——用深度学习端到端生成、音质好速度快、是AI配音的核心技术)。市面上所有AI配音工具(Azure/ElevenLabs/ttsmaker/剪映等)底层全是神经网络TTS。各厂商差异在哪——训练数据量和针对什么语言优化。
语音合成工具对比:TTS引擎的技术流派和各自的优缺点
你用的每一个AI配音工具——底层都是一个TTS引擎在工作。引擎的技术流派决定了配音的自然度天花板。
三代TTS技术对比
| 技术 | 年代 | 音质 | 速度 |
|---|---|---|---|
| 参数式 | 2000年代 | 机械音 | 快 |
| 拼接式 | 2010年代 | 好但僵硬 | 中等 |
| 神经网络式 | 2020年代 | 接近真人 | 快 |
为什么不同AI配音工具音质差那么多?
同样是神经网络TTS——Azure在中文上为什么比ElevenLabs好?因为Azure用了几十万小时中文语音数据训练,而ElevenLabs的英文数据量远超中文。TTS模型就是"吃数据长大的"——谁在这门语言上喂的数据多、数据质量高——谁的表现就好。这也是为什么小公司的AI配音永远追不上大厂——训练高质量TTS模型需要的GPU算力和数据量太大了。
常见问题
为什么不同AI配音工具的音质差那么多?
训练数据量、模型架构、针对性优化三因素。Azure用几十万小时训练中文→极好;小公司几千小时→一般。数据量和优化方向决定表现。
下次选AI配音工具的时候记住——选的是"谁在这门语言上花的数据量和计算资源最多"。这就是为什么做中文选Azure、做英文选ElevenLabs。
参考来源:学术论文