
声音克隆技术原理揭秘:AI是怎么用10秒钟音频复制你声音的
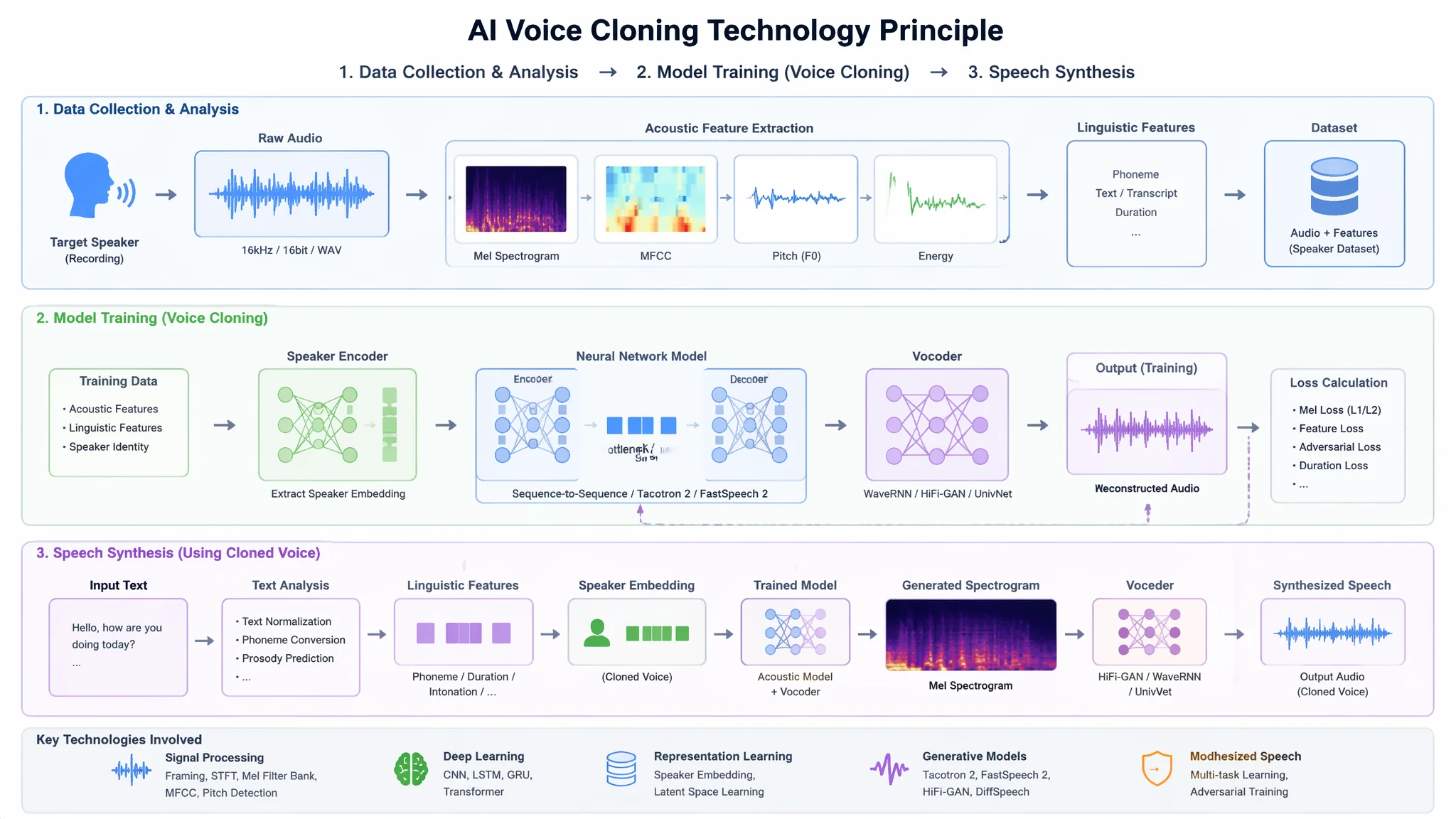
简单说:AI声音克隆看起来神奇——上传10秒音频就能复制一个人的声音。其实背后是三步流程:声学特征提取(AI分析你的音色/音调/语速特点)→声学模型微调(用你的特征数据调优一个预训练好的AI模型)→语音合成(输入任意文字,模型用你的声音特征念出来)。10秒音频做的是快速克隆(轻量微调),1小时音频做的是完整克隆——相似度从80%提到95%。
声音克隆技术原理揭秘:AI是怎么用10秒钟音频复制你声音的
录10秒自己说话→AI就能用你的声音念任何文字。这听起来像魔法。但它背后的技术逻辑其实不难理解——三个步骤,每一步都有迹可循。
三步走——AI声音克隆全流程
第1步:声学特征提取
AI拿到你的10秒录音后,不是"听你怎么说的"——而是"分析你声音的数学特征"。它会提取:基频(决定音高——你是男声还是女声、低沉还是尖细)、频谱包络(决定音色——你的声音为什么"像你"而不像别人)、语速和节奏特征、共振峰(决定口型和发音习惯)。这些特征被编码成一个"声音指纹向量"——一个几百维的数学表达,精准刻画了你的声音。
第2步:声学模型微调
有了你的声音特征向量后,把它注入一个预训练好语音合成模型(比如VITS或Coqui TTS已经用几千小时多人语音预训练过了)。这个模型之前"会说话"——但不知道你的声音是什么样的。注入你的声音特征后做轻量微调——10秒音频约200-500个参数被微调。这就是"快速克隆"——学得不够深入但快。
第3步:语音合成
微调后的模型现在"拥有了你的声音特征"。输入任意文字→模型把文字转成声音的声学参数(音高曲线、频谱图等)→用声码器把这些参数合成实际的音频波形→输出WAV/MP3。这个过程实现了"用你的声音说任何话"。
10秒 vs 1小时的差距
10秒音频约提供200-500个特征参数的学习量——AI能学到的只是"音色层级"的表面特征(音高、基本音色)。1小时音频提供几万个特征参数——AI能学到深层的发音习惯、情感表达方式、连读规则。这就是为什么1小时训练的克隆能"骗过家人"而10秒训练的只能在打电话时双方都安静不说话的情况下勉强像。
常见问题
10秒和1小时的克隆相似度差多少?
10秒快速克隆约75-85%——能听出像你但不完美。1小时完整克隆约90-95%——家人可能分不出。10秒只够抓基础音色,1小时能学语速习惯情感表达连读等深层特征。
声音克隆不是魔法——是声学特征工程+AI模型的结合。了解原理之后再用这些工具——不仅用得更顺手,还能理解它的局限在哪。关注FlowPix看更多AI技术的通俗解读。
参考来源:arXiv论文