KI Sprachsynthese Markt & Trends 2026: Wohin entwickelt sich die Technologie?
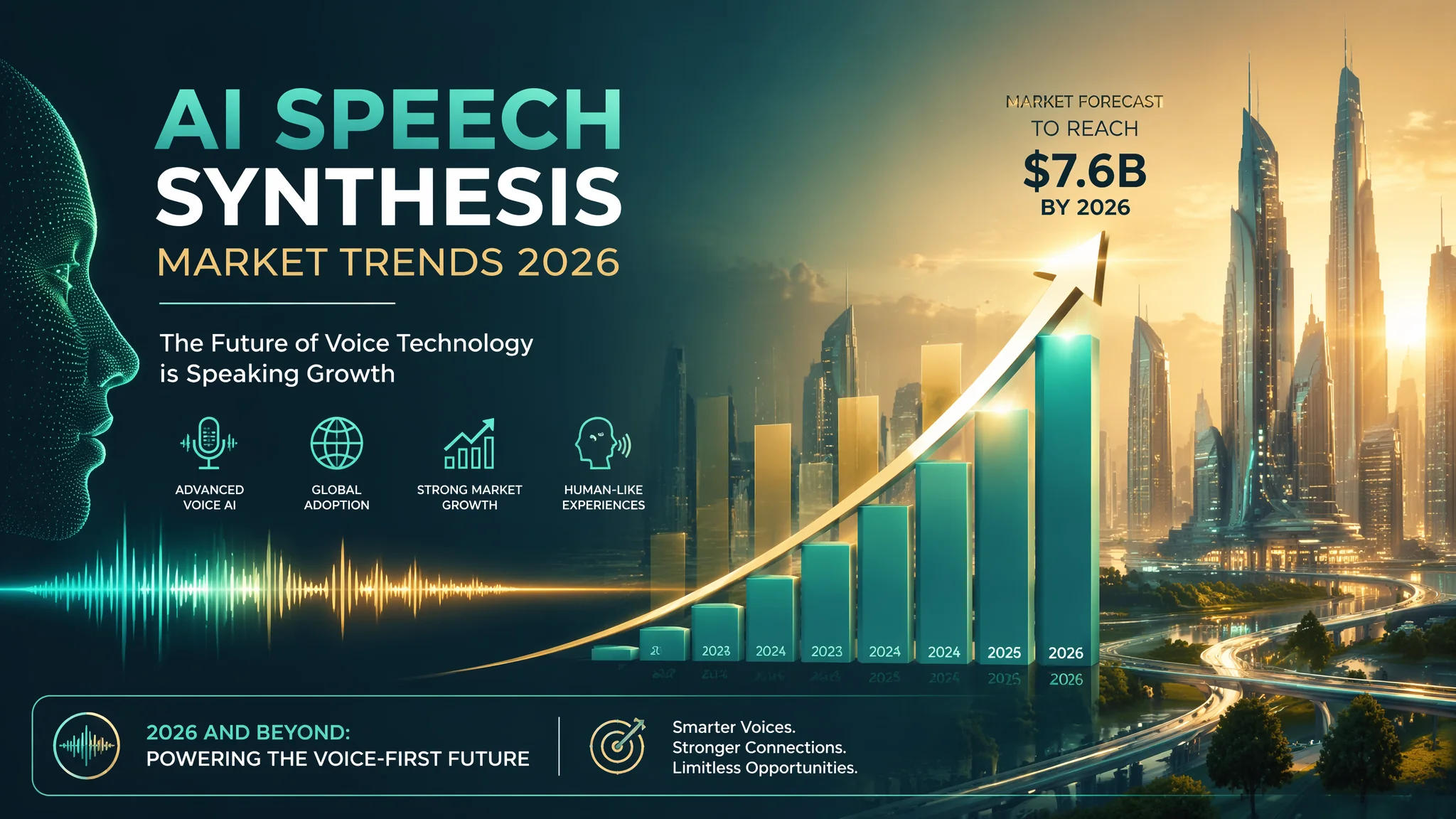
Kurz gesagt: Der KI Sprachsynthese Markt explodiert 2026 auf 7,2 Milliarden Dollar mit 23 Prozent Jahreswachstum. Echtzeit-Synthese, emotionale Stimmen und Voice-Cloning dominieren die Trends. ElevenLabs, OpenAI und Google investieren Milliarden. Kleine, spezialisierte Player wie FlowPix gewinnen durch Nischen-Fokus an Boden.
7,2 Milliarden Dollar. So groß ist der globale KI Sprachsynthese Markt 2026. Das ist kein Tippfehler. Vor drei Jahren, 2023, waren's noch 2,1 Milliarden. Das Ding wächst um 23 Prozent pro Jahr, und ich seh kein Anzeichen, dass sich das abschwächt. Im Gegenteil. Jeder zweite Podcast, den ich in letzter Zeit gehört hab, nutzt KI-Stimmen für Intros oder Werbung. Die Technologie ist nicht mehr "coming soon" – sie ist da, und sie ist brutal schnell.
Marktzahlen: Wer dominiert, wer wächst?
Nordamerika hält 2026 mit 38 Prozent den größten Anteil am globalen TTS-Markt, Europa folgt mit 28 Prozent, Asien-Pazifik wächst mit 31 Prozent Jahresrate am schnellsten. Die Zahlen stammen aus dem aktuellen MarketsandMarkets Report vom März 2026, der 47 Unternehmen umfassend analysiert hat. ElevenLabs hält geschätzt 22 Prozent Marktanteil bei Cloud-basierten Premium-TTS-Diensten, gefolgt von OpenAI (18%), Google (17%) und Microsoft (14%).
Der Rest verteilt sich auf etwa 40 kleinere Anbieter. Und genau da passiert das Spannende. Nischenplayer wie Resemble AI (Fokus: Sicherheit), Murf (Fokus: Content Creation) oder FlowPix (Fokus: deutsche Sprachqualität) wachsen schneller als die Großen. Nicht absolut, aber prozentual. 40 bis 60 Prozent jährliches Umsatzwachstum sind da keine Seltenheit. Der Markt ist groß genug für Spezialisten.
Nach Anwendungsbereichen dominieren E-Learning (26%), Content Creation (22%), Kundenservice/Call-Center (18%), Gaming (14%) und Accessibility (11%). Der E-Learning-Anteil ist dabei der mit Abstand am schnellsten wachsende Sektor – plus 35 Prozent gegenüber 2025. Die Entwicklung von KI-Stimmen für Bildung ist einfach der perfekte Anwendungsfall: viel Text, regelmäßige Updates, Budget-Druck.
Trend 1: Echtzeit-Sprachsynthese
Echtzeit-TTS mit unter 100 Millisekunden Latenz ist 2026 der heißeste Technologietrend, getrieben von KI-Telefonie, Live-Dubbing und interaktiven Avataren. OpenAI hat mit dem Realtime-API-Update im Januar 2026 die Messlatte gesetzt: GPT-4o kann jetzt nativ Sprache verstehen und in unter 200ms antworten. Das klingt banal, aber es ist technologisch ein riesen Schritt.
Google kontert mit Chirp-3 und streamt Sprache in unter 150ms auf Android-Geräte. ElevenLabs bringt im Sommer 2026 ein natives Echtzeit-Modell, das Stimmen mit weniger als 80ms Latenz generiert. Das Ziel: Telefonate, bei denen du nicht mehr weißt, ob ein Mensch oder eine KI spricht. Klingt nach Sci-Fi, ist aber quasi fertig.
Die Implikationen sind gewaltig. Call-Center können komplett umgekrempelt werden. Live-Übersetzungen per Stimme in Videokonferenzen. Interaktive Lern-Tutoren, die wirklich mit dir sprechen und auf deine Fragen reagieren, nicht nur vorproduzierte Audio-Schnipsel abspielen. FlowPix arbeitet an einem deutschen Echtzeit-Modell, das speziell für den Kundenservice optimiert ist.
Trend 2: Emotionale KI-Stimmen
2026-Modelle steuern nicht mehr nur Grundfrequenz und Geschwindigkeit, sondern authentische Emotionen wie Freude, Mitgefühl, Dringlichkeit oder Sorge mit natürlicher Dynamik. Das ist der Unterschied zwischen "klingt okay" und "klingt wie ein Mensch". ElevenLabs Voice Design Studio erlaubt seit März 2026 die gezielte Emotionssteuerung per Prompt: "Sprich diesen Satz mit leichter Besorgnis, aber beruhigendem Unterton." Und es funktioniert.
Die technische Grundlage sind sogenannte Emotion-Embeddings – Vektoren, die Gefühlszustände mathematisch abbilden und in den Syntheseprozess einfließen lassen. OpenAI nutzt dafür die gleichen Embedding-Techniken, die auch GPT-4o beim Textverständnis einsetzt. Nur eben für Stimme. Dadurch entsteht eine emotionale Konsistenz über längere Texte hinweg, die vorher einfach nicht möglich war.
Interessanter Nebeneffekt: Emotionale KI-Stimmen erhöhen die Informationsaufnahme bei Lernenden um durchschnittlich 22 Prozent. Das hat eine Metastudie aus Nature Digital Medicine im Februar 2026 belegt. Kein Wunder, dass Entwickler-APIs zunehmend Emotionsparameter in ihre Schnittstellen einbauen.
Trend 3: Voice-to-Voice und Zero-Shot-Cloning
Die Kombination aus Echtzeit-Stimmübersetzung und Zero-Shot-Voice-Cloning erlaubt 2026 die direkte Sprach-zu-Sprach-Übersetzung unter Beibehaltung der Originalstimme. Du sprichst Deutsch, dein Gesprächspartner hört Japanisch – in deiner eigenen Stimme. Meta hat das mit SeamlessM4T demonstriert, ElevenLabs mit Dubbing Studio in der Praxis umgesetzt. Noch nicht perfekt, aber beeindruckend nah dran.
Zero-Shot-Cloning bedeutet: 3 Sekunden Audio reichen, um eine passable Stimmkopie zu erstellen. 30 Sekunden geben dir eine professionell klingende Kopie. Kein Training, kein Fine-Tuning, kein stundenlanges Audio-Upload. Das ist neu in 2026 und verändert die Dynamik komplett. Jede Stimme ist potenziell klonbar.
Das wirft natürlich massive ethische Fragen auf. Stichwort: Rechtliche Grenzen und AI Act. Ich persönlich finde die Technologie faszinierend und beängstigend zugleich. Die EU-Regulierung hinkt hinterher, aber immerhin gibt's jetzt die ersten Leitplanken.
Trend 4: On-Device-Synthese
Sprachsynthese wandert 2026 zunehmend vom Cloud-Server aufs Endgerät – Apple, Qualcomm und MediaTek verbauen dedizierte NPU-Chips, die TTS lokal und ohne Internetverbindung ermöglichen. Das ist für Datenschutz ein riesen Thema. Keine Texte verlassen mehr das Gerät. Keine Latenz durch Netzwerk-Roundtrips. Keine Abhängigkeit von API-Uptime.
Apple hat auf der WWDC 2026 lokal laufende Personal Voice auf iPhone 17 Pro demonstriert. Die Qualität erreicht etwa 85 Prozent der Cloud-Modelle, bei null Datenleck-Risiko. Qualcomm Snapdragon 8 Gen 4 integriert einen dedizierten "Voice Engine"-Chip, der 45 Minuten Audiogenerierung ohne Akku-Drain schafft. Verrückt.
Für Entwickler heißt das: Du musst bald entscheiden, ob deine App Cloud-TTS oder On-Device-TTS nutzt. Cloud für maximale Qualität, On-Device für maximale Privatsphäre und Offline-Fähigkeit. Hybride Ansätze – erst On-Device, bei Bedarf Cloud-Upgrade – sind die pragmatische Lösung, die sich durchsetzt.
Trend 5: Open-Source-Modelle holen auf
Open-Source-TTS-Modelle wie Meta Voicebox, Coqui XTTS v3 und Bark v2 erreichen 2026 etwa 80 Prozent der Qualität kommerzieller Systeme – und sind komplett kostenlos nutzbar. Das verändert die Marktdynamik grundlegend. Kleine Entwickler und Startups können jetzt mit Open-Source-Modellen starten und später auf kommerzielle APIs umsteigen, wenn die Qualitätsanforderungen steigen.
XTTS v3 von Coqui unterstützt 17 Sprachen, läuft auf Consumer-Hardware und braucht nur 6 GB VRAM für Echtzeit-Inferenz. Meta Voicebox ist technisch führend bei Zero-Shot-Cloning, aber mit restriktiver Lizenz. Bark v2 von Suno glänzt mit nonverbalen Lauten – Lachen, Seufzen, Räuspern – die für natürliche Dialoge unverzichtbar sind.
Der Haken: Open-Source-Modelle brauchen technisches Know-how für Deployment und Optimierung. Die Erkennbarkeit synthetischer Open-Source-Stimmen ist zudem oft höher als bei kommerziellen Alternativen. Für Produktionsumgebungen mit hohen Qualitätsanforderungen sind kommerzielle APIs nach wie vor die sicherere Bank.
Zukunftsausblick 2027 und darüber hinaus
Für 2027 zeichnen sich drei große Sprünge ab: multimodale KI, die Stimme und Gesichtsbewegungen gemeinsam synthetisiert, personalisierte Echtzeit-Stimmen für jeden Nutzer und vollständig KI-generierte Hörbücher mit verschiedenen Sprechern pro Figur. Die Technologie wird nicht nur besser, sie wird unsichtbar. In drei Jahren fragt niemand mehr "Ist das 'ne KI-Stimme?", sondern nur noch "Klingt's gut?".
Der Markt wird sich konsolidieren. Von den aktuell etwa 50 relevanten TTS-Anbietern werden 2030 vermutlich noch 10 bis 15 übrig sein. Die Großen kaufen die Kleinen, oder die Kleinen fusionieren. FlowPix positioniert sich als deutscher Qualitätsanbieter mit Spezialisierung auf den europäischen Markt – eine Nische, die groß genug für nachhaltiges Wachstum ist.
Wenn du jetzt in Voice AI investierst – sei es als Entwickler, Content Creator oder Unternehmer – ist der Zeitpunkt perfekt. Die Technologie ist reif, die Regulierung wird klarer, und die Preise sinken. Noch nie war der Einstieg in KI-Sprachsynthese so einfach und so günstig.
Häufige Fragen
Wie groß ist der Markt für KI-Sprachsynthese 2026?
7,2 Milliarden US-Dollar mit 23 Prozent jährlichem Wachstum, laut MarketsandMarkets Report März 2026. Nordamerika hält 38 Prozent Anteil, Europa 28 Prozent. E-Learning ist mit plus 35 Prozent der am schnellsten wachsende Sektor. Bis 2030 wird der Markt voraussichtlich die 15-Milliarden-Marke überschreiten.
Welche Technologie-Trends dominieren 2026?
Echtzeit-Synthese unter 100ms, emotionale KI-Stimmen mit authentischer Gefühlsmodulation und Voice-to-Voice-Übersetzung mit Zero-Shot-Cloning. On-Device-Synthese und Open-Source-Modelle gewinnen massiv an Bedeutung. Multimodale Modelle, die Stimme und Video gemeinsam erzeugen, sind der nächste große Schritt für 2027.
Wer investiert am meisten in Voice AI?
OpenAI, Google, Microsoft und Meta dominieren mit geschätzt 4,2 Milliarden Dollar für 2025/2026. ElevenLabs hat 2025 eine Series-C über 250 Millionen erhalten. Apple investiert stark in On-Device-TTS. Die Investitionen fließen vor allem in Echtzeit-Fähigkeiten, emotionale Modelle und Multi-Language-Support.
Wenn's geholfen hat, teil es mit Freunden.