AI音声合成技術の仕組み入門2026:ディープラーニングで声が生まれるまで
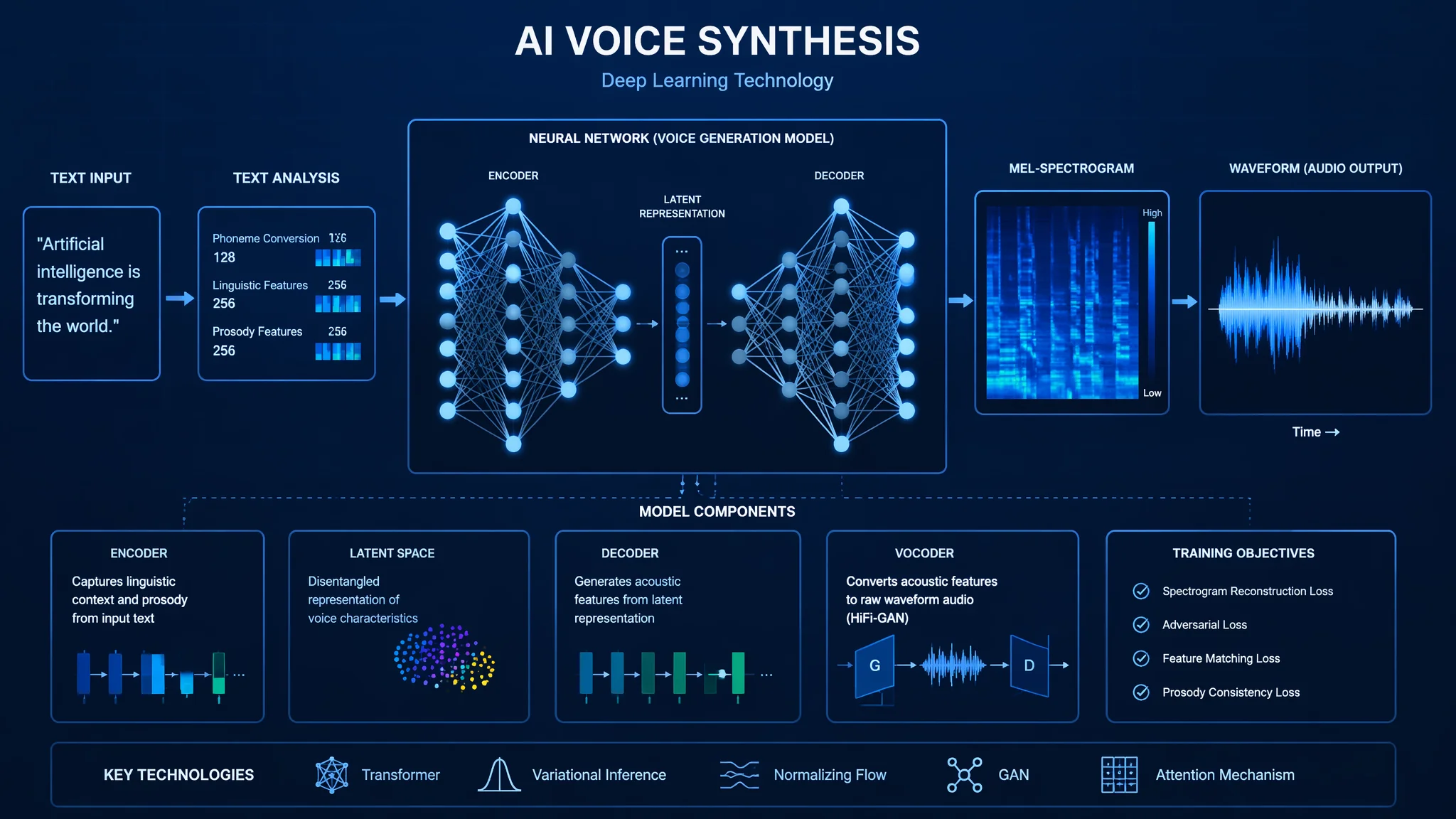
ひとことで言うと:AI音声合成は「テキスト解析→音響モデル→波形生成」の3ステップ。難しい数式なしで、誰でも理解できるように仕組みを解説します。なぜ最近のAI音声はこんなに自然なのか、その秘密がわかります。
「AIってどうやって声を出してるの?喋る仕組みが気になる」と言われたことがあります。
確かに不思議ですよね。テキストを入れたら人間の声が出てくる。この記事ではAI音声合成技術の仕組みを、技術者じゃなくてもわかるように解説します。
全体像:3ステップで声ができる
AI音声合成の基本は「テキスト解析→音響特徴量の予測→音声波形の生成」の3段階です。それぞれの役割を料理に例えると…
- テキスト解析(レシピを読む):入力された文章をAIが解析して「この単語はこう発音する」という情報に変換。
- 音響モデル(調理計画を立てる):声の高さ・抑揚・話す速度・感情などを予測。ここがAIの頭脳。
- ボコーダー(実際に調理する):予測された特徴量から実際の音声波形を生成。最終的に耳に届く音を作る。
テキスト解析:AIは文章をどう読むか
AIはまず入力テキストを「音素(フォニーム)」という発音の最小単位に分解します。「こんにちは」は「k/o/n/n/i/ch/i/w/a」の9音素に分解される。
日本語は特に「漢字の読み」が難しい。「明日」は「あした」なのか「あす」なのか「みょうにち」なのか。AIは前後の文脈から最も適切な読みを推測する。ここで上手くいかないと「棒読みAI」になってしまう。
WaveNetとTacotron:2大技術の違い
AI音声合成の品質を劇的に向上させた2大技術がWaveNetとTacotronです。簡単に言うとTacotronが「楽譜」を書いて、WaveNetが「演奏する」役割。
Tacotron(Google、2017年)はテキストを入力するとスペクトログラム(音の設計図)を出力する「音響モデル」。WaveNet(DeepMind、2016年)はその設計図から実際の音声波形を1サンプルずつ生成する「ボコーダー」。
2026年現在は両者を統合した「エンドツーエンドTTS」(VITSやFastSpeechなど)が主流。これが今の自然なAI音声の正体です。技術的な詳細は DeepMindのWaveNet論文 を参照。
なぜ最近こんなに自然になったのか
3つの技術革新がAI音声の品質を飛躍的に向上させました。大量データ学習・波形直接生成・文脈理解の進化です。
数千時間の音声データでトレーニングされたモデルは、人間の声の微細なニュアンスまで再現可能に。さらにTransformerアーキテクチャ(ChatGPTと同じ仕組み)の導入で、文章全体の文脈を理解した自然な抑揚が実現しました。
最新トレンドについては AIナレーション最新トレンド もどうぞ。
よくある質問
AI音声合成はどうやって声を作っているのですか?
大まかには「テキスト解析→音響特徴量の予測→音声波形の生成」の3ステップです。まずテキストを解析して発音情報に変換、次にAIが声の高さ・抑揚・話速などの特徴量を予測し、最後にボコーダーがそれを実際の音声波形に変換します。
WaveNetとTacotronの違いは何ですか?
Tacotronはテキストから音響特徴量(スペクトログラム)を生成するモデルで、WaveNetはその特徴量から実際の音声波形を生成するモデルです。Tacotronが「楽譜」を書き、WaveNetが「演奏する」イメージ。最近は両者を統合したエンドツーエンドモデルが主流です。
なぜAI音声はこんなに自然になったのですか?
3つの技術革新が鍵です。1つ目は大量の音声データで学習できるディープラーニング、2つ目は波形を直接生成できるニューラルボコーダー、3つ目はTransformerなどの注意機構による長文の文脈理解。これらが組み合わさって、2020年代後半に劇的な品質向上を遂げました。
役に立ったら友達にシェアしてね。