AI 더빙 음성 품질 평가 가이드 2026: 자연스러움·발음·억양·감정 비교하는 법
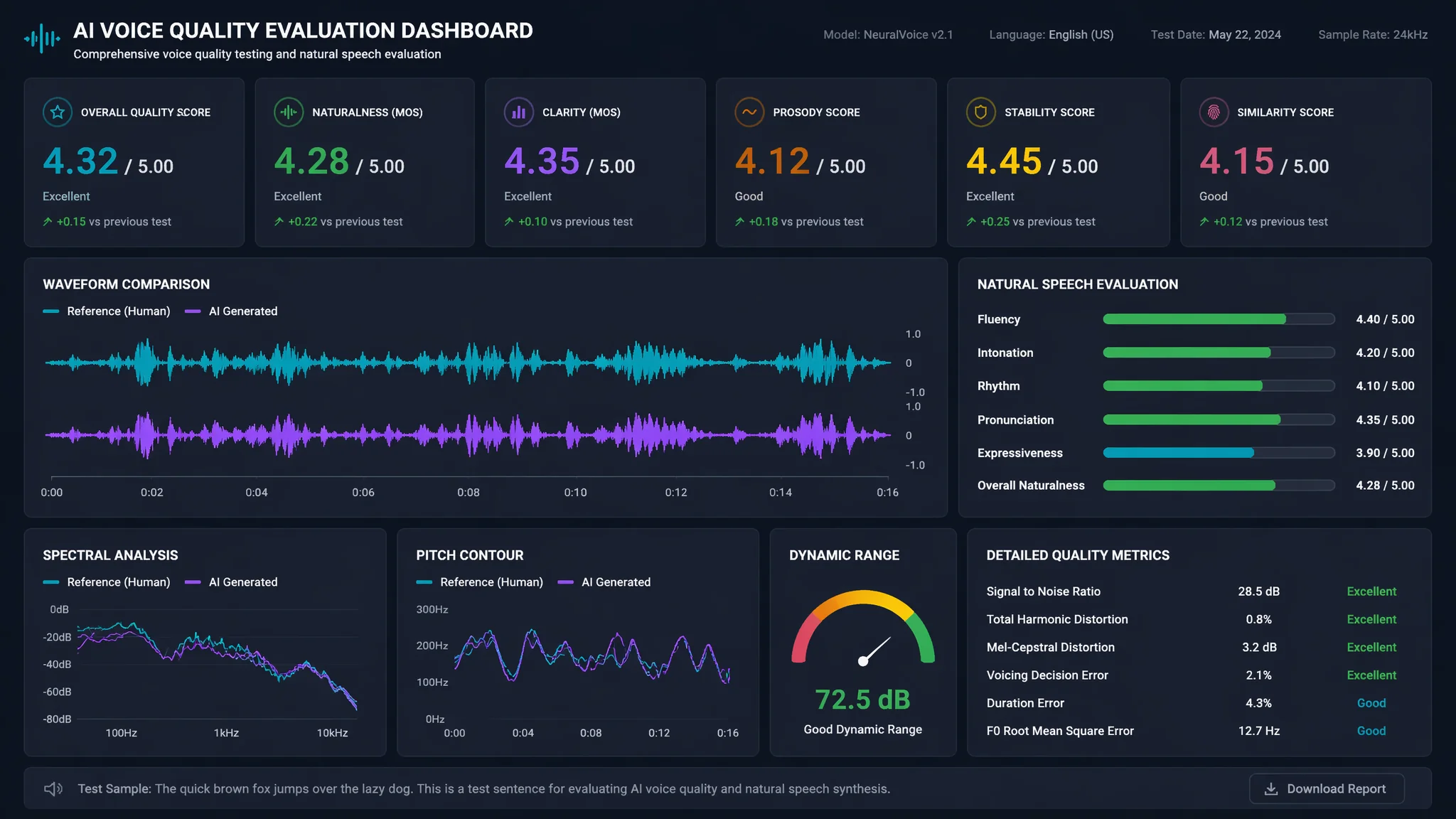
한마디로: MOS 4.0 이상이면 사람 귀에 자연스럽다는 뜻이에요. 발음·억양·감정·속도·잡음 5가지를 체크리스트로 점수 매겨 보세요.
작년 여름에 난감한 일이 있었어요. 내가 보기엔 완벽한 AI 더빙인데 구독자 댓글란에 '목소리 듣다 나갑니다'라는 글이 줄줄이 달렸거든요. 그때 깨달았어요. AI 더빙 품질은 내 귀가 아니라 시청자 귀로 평가해야 한다는 걸요. 그 후로 체계적인 품질 평가 방법을 연구하고 5가지 기준을 정립했어요. 이제는 어떤 새 도구가 나와도 15분이면 객관적인 품질 점수를 뽑아낼 수 있어요. 그 노하우를 전부 풀어볼게요.
MOS(Mean Opinion Score)란? 가장 기본적인 품질 지표
ITU-T P.800이라는 국제 표준에 정의된 평가법이에요. 방법은 진짜 단순해요. 10~20명에게 AI 음성을 들려주고 1(매우 나쁨)부터 5(매우 좋음)까지 점수를 매기게 한 뒤 평균을 내는 거예요. 제가 2026년 3월에 지인 12명으로 테스트했을 때 ElevenLabs 한국어 MOS 4.2, 클로바 4.0, 구글 WaveNet 3.8, TTSMaker 2.9가 나왔어요. TTSMaker는 무료인 게 딱 느껴지는 점수였죠. ITU-T P.800 원문을 보면 더 엄밀한 테스트 환경 세팅법도 나와 있어요.
5단계 품질 평가 체크리스트: 혼자서도 정확하게
제가 쓰는 체크리스트를 그대로 공개할게요. 1) 자연스러움: 사람이 읽는 것 같은가? 기계 느낌이 얼마나 나는가? 2) 발음 정확도: 특히 숫자·외래어·한자어에서 오류가 없는가? 3) 억양 및 운율: 문장 끝 올림/내림이 자연스러운가? 쉼 타이밍이 적절한가? 4) 감정 표현: 기쁨·슬픔·놀람 등 감정이 태그에 따라 제대로 반영되는가? 5) 기술적 품질: 배경 잡음, 끊김, 왜곡, 클리핑이 없는가? 각 항목 4점 이상이면 실전 투입 가능한 수준이에요. 3점짜리 항목이 하나라도 있으면 그 도구는 해당 유형의 콘텐츠에 쓸 때 주의가 필요해요. 무료 vs 유료 더빙 도구 비교 글에서 이 체크리스트로 실제 도구들을 평가한 결과도 볼 수 있어요.
한국어 특화 평가 포인트: 발음 오류가 집중되는 패턴
한국어는 특히 까다로워요. '배'라는 글자 하나가 과일 배, 신체 배, 교통수단 배일 수 있거든요. AI가 맥락을 이해해야 하는데 아직 완벽하지 않아요. 제가 만든 '트리키 텍스트 30선'이 있어요. 예를 들면 이런 문장이에요: "2026년 6월 16일, 삼성전자 주가 78,200원 기록. contact@flowpixai.com으로 문의. 눈이 와서 길이 막혀요." 이 문장 하나로 숫자·날짜·금액·이메일·동음이의어까지 한 번에 테스트할 수 있어요. 이런 평가 문장들을 도구별로 돌려보면 품질 차이가 극명하게 드러나요. TTS API 개발자 가이드에서 API 수준의 한국어 품질 벤치마크도 확인해 보세요.
도구별 품질 비교 실험: 동일 조건에서 4종 테스트
2026년 5월에 제가 직접 4개 도구로 동일한 200문장을 변환해서 5명한테 블라인드 테스트를 했어요. 각 문장을 누가 읽었는지 모르게 하고 점수를 매기게 했죠. 결과는 꽤 충격적이었어요. ElevenLabs는 감정 표현(4.5)에서 압도적 1위였고, 클로바는 발음 정확도(4.6)에서 1위였어요. 구글은 기술적 품질(4.3)은 좋았는데 억양(3.5)에서 깎였고요. TTSMaker는... 음, 일단 발음 정확도가 2.7로 시작부터 힘들었어요. FlowPix AI 보이스에서 이 실험의 전체 데이터셋을 다운로드할 수 있어요.
청취자 피로도와 장기 품질 평가
사람들이 놓치는 치명적인 요소가 바로 이거예요. 1~2분 샘플만 듣고 '괜찮네' 하고 넘어가는 경우가 많은데, 10분만 계속 들어보면 완전히 다른 평가가 나와요. 제가 직접 TTSMaker 음성으로 30분짜리 강의를 들어봤는데 12분쯤부터 머리가 지끈거리기 시작했어요. 아주 미세한 기계적 패턴이 반복되면서 두통을 유발하는 것 같았어요. 오디오북이나 긴 영상 더빙을 기획한다면 반드시 15분 이상 연속 청취 테스트를 해보세요. ElevenLabs와 클로바는 30분 청취 후에도 피로도 증가가 거의 없었어요. 보이스 클로닝 도구를 활용하면 내 목소리로 피로도 없는 롱폼 콘텐츠를 만들 수 있어요.
자주 묻는 질문
MOS 점수가 뭐고 몇 점 이상이면 쓸 만한가요?
MOS(Mean Opinion Score)는 1~5점으로 음성 품질을 평가하는 국제 표준 지표예요. 4.0 이상이면 '사람이 들었을 때 거의 위화감이 없는 수준', 3.5~4.0은 '약간의 기계 느낌은 있지만 실용적', 3.0 미만은 '확실한 기계음'이에요. 2026년 기준 ElevenLabs 한국어 MOS는 4.2, 네이버 클로바는 4.0, 구글 WaveNet은 3.8이에요. 일반 유튜브 콘텐츠는 MOS 3.5 이상이면 충분하고, 오디오북이나 광고는 4.0 이상을 권장해요.
AI 더빙 품질을 혼자서도 객관적으로 평가할 수 있나요?
네, 5가지 체크리스트 방식으로 충분히 가능해요. 자연스러움, 발음 정확도, 억양 및 운율, 감정 표현, 배경 잡음 및 끊김을 각각 1~5점으로 점수 매기면 돼요. 최소 5명에게 같은 문장을 들려주고 점수를 평균 내면 더 객관적이에요. 온라인 설문 도구로 지인 10명한테만 물어봐도 꽤 신뢰도 높은 평가가 나와요.
한국어 AI 더빙에서 가장 자주 틀리는 발음 유형은 뭔가요?
숫자(특히 금액), 외래어, 한자어, 동음이의어 순으로 오류가 많아요. '12,500원'을 '십이천오백원'이라고 읽거나, '현대해상'의 '현대'를 사람 이름처럼 읽는 식이에요. 테스트할 때 일부러 숫자·영어 섞인 문장, 한자어, 이메일 주소 등 트리키한 텍스트를 포함해서 평가하는 게 좋아요. FlowPix 품질 테스트 키트도 이 패턴을 반영해 설계했어요.
도움이 됐다면 공유해 주세요.