A/B测试提示词方法:科学验证哪种写法效果最好的完整流程
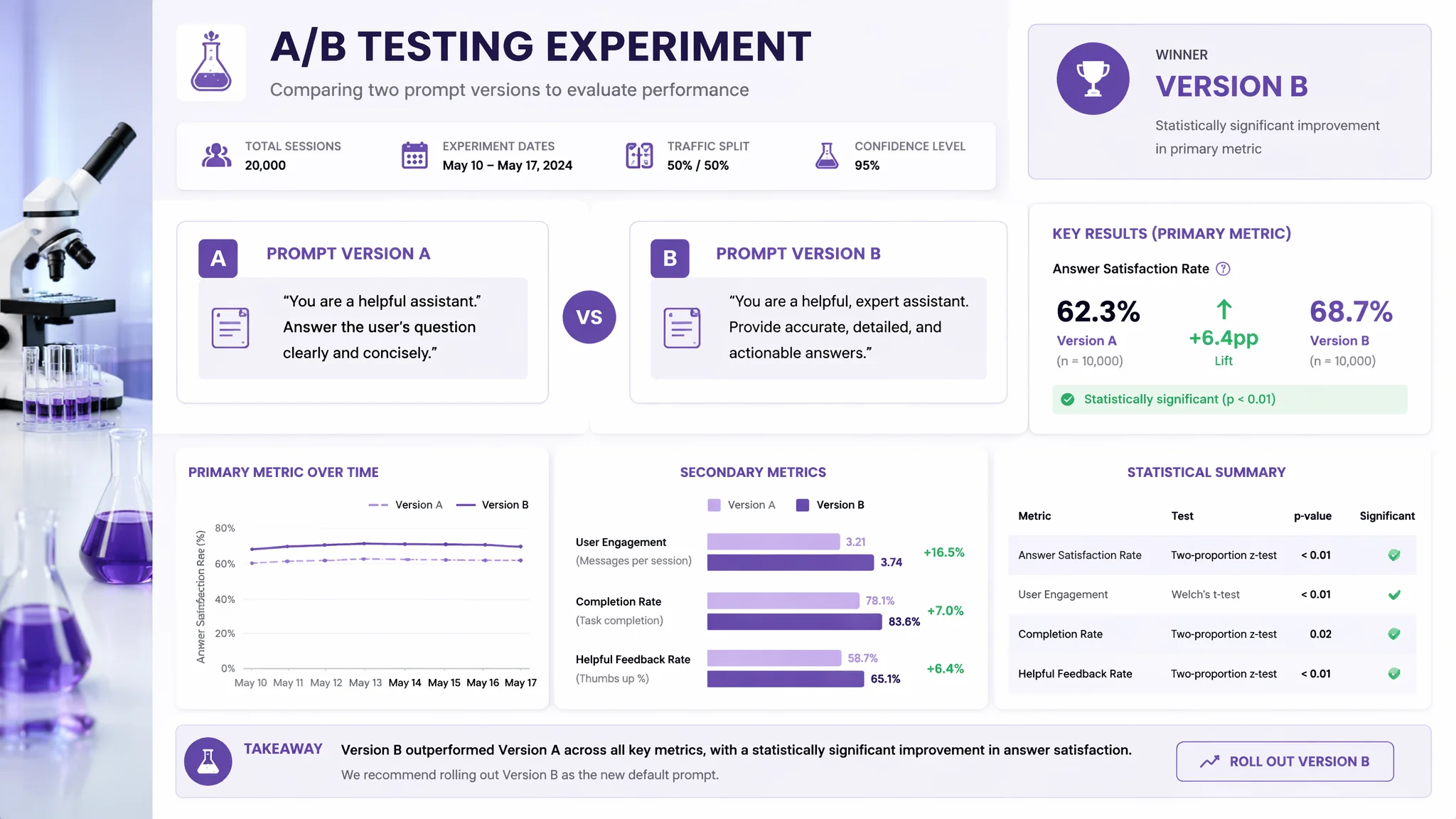
简单说:A/B测试提示词就是把两个不同写法的prompt分别跑同一批测试数据,用量化分数判断哪个更好。告别"感觉A比B好一点"的主观判断。需要的工具:一个测试集+评分标准+一点统计知识。
A/B测试提示词方法:科学验证哪种写法效果最好的完整流程
我见过太多人改prompt的方式是这样的——改一句→试一次→"嗯好像好了一点"→继续改→试到满意→上线。问题是,"感觉好了一点"里有多少是真的改善、多少是你的心理暗示?
A/B测试把这层朦胧的感觉换成冷冰冰的数字。我刚开始嫌麻烦,后来真做了才发现:有一些我"感觉有用"的改法其实是在倒退。
A/B测试提示词的4步流程
标准流程:准备测试集→定义评分标准→跑两个版本统计得分→判断差异是否显著。听起来像科研实验,但其实半小时就能跑完一轮。
第1步:准备测试集(最少20条,推荐50条)
测试集就是一堆"输入→期望输出"的配对数据。如果你做的是文案生成任务,测试集应该包含20-50条典型的用户输入和你认为好的输出。注意:测试集要覆盖边缘case,不只是典型case——A/B测试最容易发现的差异往往在边缘情况上。
测试集一旦定下来,整个实验周期都不能改。改了就没法对比了。
第2步:定义评分标准
分任务类型来:
| 任务类型 | 评分方法 | 示例 |
|---|---|---|
| 分类/判断 | 准确率 = 正确数/总数 | 情感分析判断对了几条 |
| 格式提取 | 格式合法性(JSON有效/无效) | 返回的JSON能不能parse |
| 文本生成 | 1-5分人工评分(至少2个维度) | 相关性+流畅度+信息完整性 |
| 代码生成 | 通过率 = 运行通过数/总数 | 生成的代码能不能跑通 |
FlowPix内部的文本生成评分用了三个维度:相关性(回答是否对应问题)、完整性(是否遗漏关键信息)、自然度(是否像人写的)。每个维度1-5分,取平均。
第3步:跑实验
同一个测试集,用Prompt A跑一遍,Prompt B跑一遍。关键:temperature设成0(或者至少固定住同一个值)。如果每次运行temperature不同,你根本不知道差异来自prompt改动还是随机性。
第4步:判断差异是否显著
我最开始做A/B测试时犯的错误——直接比平均值。Prompt A平均3.8分,Prompt B平均4.1分。好!B赢了!……然后我用统计检验一算,p=0.23。不显著。这个差异可能只是随机波动。
正确的做法是用配对t检验(paired t-test),Python代码超简单:
from scipy import stats
scores_a = [4, 3, 5, 4, 3, ...] # Prompt A的20条评分
scores_b = [5, 3, 5, 5, 4, ...] # Prompt B的20条评分
t_stat, p_value = stats.ttest_rel(scores_a, scores_b)
if p_value < 0.05:
winner = "B" if sum(scores_b) > sum(scores_a) else "A"
print(f"{winner}版本显著更优 (p={p_value:.4f})")
else:
print(f"无显著差异 (p={p_value:.4f}),需更多数据")
p值小于0.05才算"显著差异",大于0.05只能说明你还需要更多测试数据。很多肉眼看着"明显更好"的结果,统计一算就是不显著。
一个真实案例:改一句prompt提升了12%
FlowPix内部有个"产品卖点提取"任务,从商品描述里提取3个核心卖点。原始版本A的prompt是:
【版本A】
从以下商品描述中提取3个核心卖点。
【版本B】
从以下商品描述中提取3个核心卖点。卖点必须是具体的功能或参数,
不能是"品质好""性价比高"这种空洞描述。
就用B比A多了一句话。跑50条测试数据:
| 指标 | 版本A | 版本B |
|---|---|---|
| 平均得分(1-5) | 3.4 | 3.8 |
| "空洞卖点"比例 | 31% | 8% |
| p值 | 0.003(显著) | |
一句话,空洞卖点从31%降到8%,整体质量提升了12%。不跑A/B测试我可能会觉得"加不加这句话无所谓"。
完整的Python测试脚本(复制即用)
这个脚本可以直接用来测你自己的prompt:
import openai
from scipy import stats
import json
client = openai.OpenAI(api_key="YOUR_KEY")
PROMPT_A = """你的Prompt版本A"""
PROMPT_B = """你的Prompt版本B"""
TEST_CASES = [
{"input": "测试输入1", "expected": "期望输出1"},
{"input": "测试输入2", "expected": "期望输出2"},
# ... 至少20条
]
def run_test(prompt_template, test_cases):
scores = []
for case in test_cases:
full_prompt = f"{prompt_template}\n\n输入:{case['input']}"
resp = client.chat.completions.create(
model="gpt-4o", messages=[{"role":"user","content":full_prompt}],
temperature=0
)
output = resp.choices[0].message.content
# 这里换成你自己的评分逻辑
score = your_score_function(output, case['expected'])
scores.append(score)
return scores
scores_a = run_test(PROMPT_A, TEST_CASES)
scores_b = run_test(PROMPT_B, TEST_CASES)
t_stat, p_value = stats.ttest_rel(scores_a, scores_b)
print(f"A平均分: {sum(scores_a)/len(scores_a):.2f}")
print(f"B平均分: {sum(scores_b)/len(scores_b):.2f}")
print(f"p值: {p_value:.4f} {'✓显著' if p_value < 0.05 else '✗不显著'}")
常见翻车姿势(我都踩过)
- 一次改太多变量——同时改了角色设定+输出格式+温度参数。跑出来结果好了,但不知道哪个改动起了作用。A/B测试必须一次只改一个变量。
- 测试集太少——10条数据跑出差异就下结论。10条数据够干啥?随机波动完全能覆盖你看到的变化。
- 测试集和实际使用场景不匹配——用教科书水平的测试集跑出好结果,上线后真实用户输入全是口语+错别字,直接翻车。
- 没固定temperature——同一个prompt跑两次结果不一样,以为是prompt改进了,其实是随机性。
常见问题
A/B测试提示词需要多少条测试数据?
最少20条,推荐50-100条。A/B测试需要统计显著性——数据太少的话,结果可能是随机的。对于分类/判断类任务,30条是最小可接受量;对于文本生成类任务,建议50条以上,因为人工评分的主观性需要更多样本对冲。
怎么判断A/B测试结果是真实差异还是随机波动?
用统计学中的配对t检验(paired t-test)来判断。简单理解:计算两个版本在每条测试数据上的得分差,如果得分的平均差异显著偏离0(p值<0.05),就是真实差异。Python中一行scipy.stats.ttest_rel就能算。如果只是肉眼比较平均值,很容易被随机波动误导。
A/B测试应该同时测几个变量?
每次只改一个变量。如果你同时改了角色设定、输出格式和示例数量,即使效果有提升,你也说不清是哪个改动带来的。这是A/B测试最基本的原则——控制变量。多变量测试需要更大的样本量,通常不推荐在prompt优化中做。参考 Anthropic的Prompt Evals指南。
觉得有用的话分享给也在优化prompt的朋友。5篇提示词工程系列到此完结,接下来聊聊AI绘画方面的话题。