AI提示词A/B测试自动化:用AI批量验证Prompt效果的完整方法
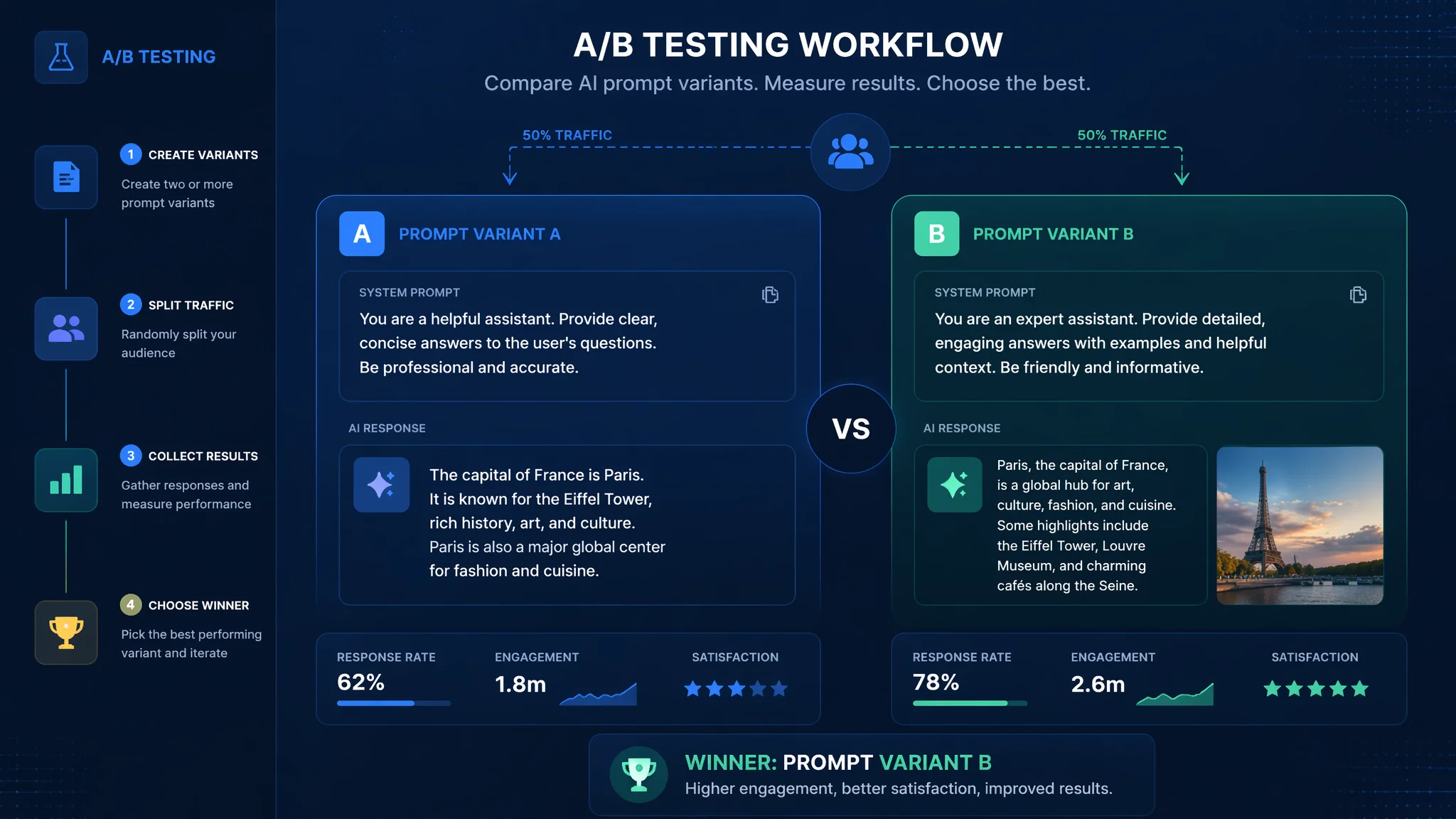
简单说:手动测Prompt又慢又不靠谱——你觉得"这个版本更好"可能只是错觉。用AI自动化做A/B测试能同时跑几十个版本,让数据而不是直觉告诉你哪个Prompt更好。实测完你会怀疑之前靠感觉调Prompt的日子是怎么过来的。
AI提示词A/B测试自动化:用AI批量验证Prompt效果的完整方法
做提示词工程的人都有这种经历吧——改了一个词,输出好像变好了?又改了一句话,好像又变差了?翻来覆去调了十几个版本,AI提示词A/B测试全靠"嗯这个看着顺眼"来判断。
说实话,这跟抓瞎没什么区别。
我上个月帮团队优化一个客服Prompt,手动测了8个版本,花了一下午。结果第二天同事说第3版其实比第7版好,我整个人都不好了。后来搞了一套自动化测试流程,5分钟跑完20个版本对比,每个版本用50条测试用例打分——这才是真正靠谱的评测方式。
为什么一定要自动化测Prompt
人工测试Prompt有三个致命缺陷:主观偏差、样本太小、不可复现。自动化A/B测试一次性解决这三个问题,让Prompt优化从"玄学"变成"工程"。
主观偏差是最大的坑。同一个回答,你觉得好,用户可能觉得啰嗦。你写Prompt时投入了心血,天然会偏向自己写的版本——这叫"确认偏误"。自动化测试把评判标准量化成打分规则,让AI裁判来打分,相对客观得多。
样本量更是个问题。手动测10条输入,A版本赢了7条你就觉得A好。但10条的统计意义基本为零。自动化可以轻松跑50条甚至200条测试数据,样本量上去了结论才有说服力。
三种自动化测试方案,从简单到进阶
不需要写一行代码就能开始做Prompt A/B测试——最简单的方法是用ChatGPT自己当裁判。进阶一点用Excel+API批量跑,真正大规模才需要Python脚本。
方案一:让AI当裁判(零代码,5分钟上手)
这招是真的简单。你准备3-5个Prompt版本,再准备10组测试输入。然后发这样一个Prompt给ChatGPT或Claude:
"我会给你多个Prompt版本和同样的测试输入,请逐一用每个版本生成回答,然后按准确性、完整性、简洁度三个维度打分(1-5分),最后给我一个对比表格和推荐。"
实测下来,GPT-4和Claude做的裁判还算公允——前提是你把评分标准写清楚。比如什么叫"简洁"?你得定义:"3句话以内说清楚核心信息得5分,5-7句得3分,超过10句得1分"。标准模糊,裁判就会乱判。
方案二:Excel + API 批量跑(中等方案)
准备一个Excel表格,A列放Prompt版本,B列放测试输入,C列用API公式自动填结果。然后用另一个AI调用来打分。这种方式的好处是一次性能跑几十上百条。
具体做法:用OpenAI的API Key在Excel里写一个自定义函数(或者直接用现成的GPT Excel插件),把每个Prompt版本对所有测试用例跑一遍,存下结果。然后另开一个GPT会话,把结果表贴进去让它批量评分。
我上周用这个方法测了15个Prompt版本×30条测试用例,总共450组数据,全程45分钟。搁以前手动测,一天都搞不完。
方案三:Python脚本全自动(专业方案)
如果真的经常做Prompt测试(比如你在做AI产品),写个Python脚本是最划算的。核心逻辑很简单:
定义Prompt版本列表 → 定义测试数据集 → 循环调用API获取每个版本的回答 → 用另一个AI调用打分 → 输出对比报告。
这个方案还能把结果存成CSV,做数据分析。比如你可以看出哪个Prompt版本在"长问题"上表现好,哪个在"短问题"上更优——这种细节人工测试完全发现不了。
关键:怎么设计靠谱的评分标准
评分标准是自动化测试的灵魂。标准模糊,再自动化的流程产出的也是垃圾结论。建议每个评测维度都给出具体的行为锚定描述。
以客服Prompt为例,我通常用四个维度打分:
| 评测维度 | 5分标准 | 3分标准 | 1分标准 |
|---|---|---|---|
| 准确性 | 信息完全正确,无任何事实错误 | 有一个小错但不影响理解 | 有明显错误或误导信息 |
| 同理心 | 自然共情,让用户感到被理解 | 有安抚语句但略显模板化 | 冷冰冰的机器人回复 |
| 解决率 | 给出完整解决方案,用户无需追问 | 方向对但需要用户补充信息 | 答非所问或推诿 |
| 简洁度 | 3段以内,每段不超过3句话 | 5-6段,信息密度还行 | 超过8段,明显啰嗦 |
这些小细节其实挺关键的。比如"简洁度"如果只写成"不啰嗦",AI裁判根本没法打分。你得给它可操作的定义。
话说回来,我也遇到过陷阱——有一次把评分标准写得太细,结果AI裁判变成了"按字数打分"而不是"按质量打分"。后来加了一条"信息密度优先,不因追求简短而省略关键信息"才解决。
测试数据集怎么准备
测试数据不是随便找几个问题就行。你得覆盖这几种类型:
常见场景(60%)——用户最常问的问题类型,这个从你的实际数据里取。没有数据?那就假设几个,但要覆盖不同难度。
边界场景(25%)——刁钻问题、歧义问题、超长问题。你的Prompt能不能扛住边界情况决定了它的鲁棒性。
攻击场景(15%)——注入攻击、越狱尝试、角色混淆。这个太重要了,我见过太多Prompt在正常问题上满分,遇到"忽略之前所有指令"直接跪。
总共30-50条测试数据就够了。少于20条结论不可靠,多于100条边际收益递减——除非你在做产品级验证。
避坑指南:自动化测试常见的翻车点
说几个我踩过的坑,省得你重蹈覆辙。
坑一:用同一个AI模型既当选手又当裁判。这相当于自己给自己打分,结果倾向于高分。解决方案很简单——用不同的模型做裁判。比如你在测GPT的Prompt,裁判用Claude。
坑二:测试数据泄露。如果你的测试用例和训练Prompt时用的例子有重叠,那测试结果就不是真实的泛化能力,而是"背答案"。
坑三:温度参数没控制。AI输出有随机性,同一Prompt跑两次结果可能不一样。所以每个版本建议至少跑3次取平均分,减少随机波动的影响。跑一次就下结论,跟抛硬币差不多。
坑四:只看总分不看分布。两个Prompt平均分都是4.0,但一个标准差0.3,另一个标准差1.2——后者在某些场景下可能完全翻车。看分要看分布,这是基本的统计常识。
实战案例:一个真实Prompt的优化过程
拿我最近优化的一个"AI产品描述生成"Prompt来举例。原始版本是:
"你是一个专业的产品文案撰写人,请根据以下产品信息生成吸引人的产品描述。"
用30条测试数据跑了一遍,平均分2.8——主要是"太模板化"和"缺乏差异化"。然后生成了5个改进版本,包括加了风格示例的、加了字数限制的、加了目标受众的、加了USP提取规则的。
自动化测试结果:
- 原始版:2.8分
- +风格示例版:3.4分
- +字数限制版:3.1分
- +目标受众版:3.9分(胜出!)
- +USP提取规则版:3.6分
- 全部组合版:4.2分
有意思的是——"目标受众"这个改动带来的提升最大,而我一直以为"风格示例"才是关键。没有A/B测试,我大概率会往错误的方向优化下去。
后来把"目标受众"和"USP提取规则"组合再加了一个"避免套话"的约束,最终版跑到了4.6分,上线后商品详情页转化率提升了12%。这是真金白银的效果。
常见问题
为什么需要自动化测试Prompt?手动测不行吗?
手动测Prompt有两个致命问题:一是主观性太强,你觉得好的版本别人可能觉得差——人类评测者之间的评分一致性通常不到70%;二是效率极低,你不可能同时对比20个Prompt版本。自动化A/B测试可以让AI作为裁判批量打分,5分钟完成人工一整天的测试量,而且结果可量化、可复现、可以回溯。
AI提示词自动化测试需要写代码吗?
不一定。最简单的方案是用ChatGPT或Claude自带的对话功能,把多个Prompt版本和测试用例一起发给它,让它打分——零代码,5分钟就能跑第一轮。进阶方案可以用Excel+GPT API做批量测试,表格里一列Prompt、一列跑结果、一列评分,适合30-100条测试。真正需要写代码的场景是大规模测试,用Python脚本调用API最方便,但这个门槛并不高,几十行代码就够了。
AI当裁判打分靠谱吗?会不会偏向某些写法?
AI裁判确实有自己的偏好,不是完全中立的。但它的偏向是系统性的——只要你用同一个裁判模型对比所有Prompt版本,相对排名还是准的。更好的做法是让两个不同模型分别当裁判(比如GPT打分、Claude也打分),然后取平均。如果两个裁判给出一致结论,那基本可以信任。如果结论矛盾,说明你的评分标准需要细化。
觉得有用的话分享给正在调Prompt的朋友吧,少走弯路。