Claude和Gemini提示词技巧:别把GPT的写法硬套到其他模型上
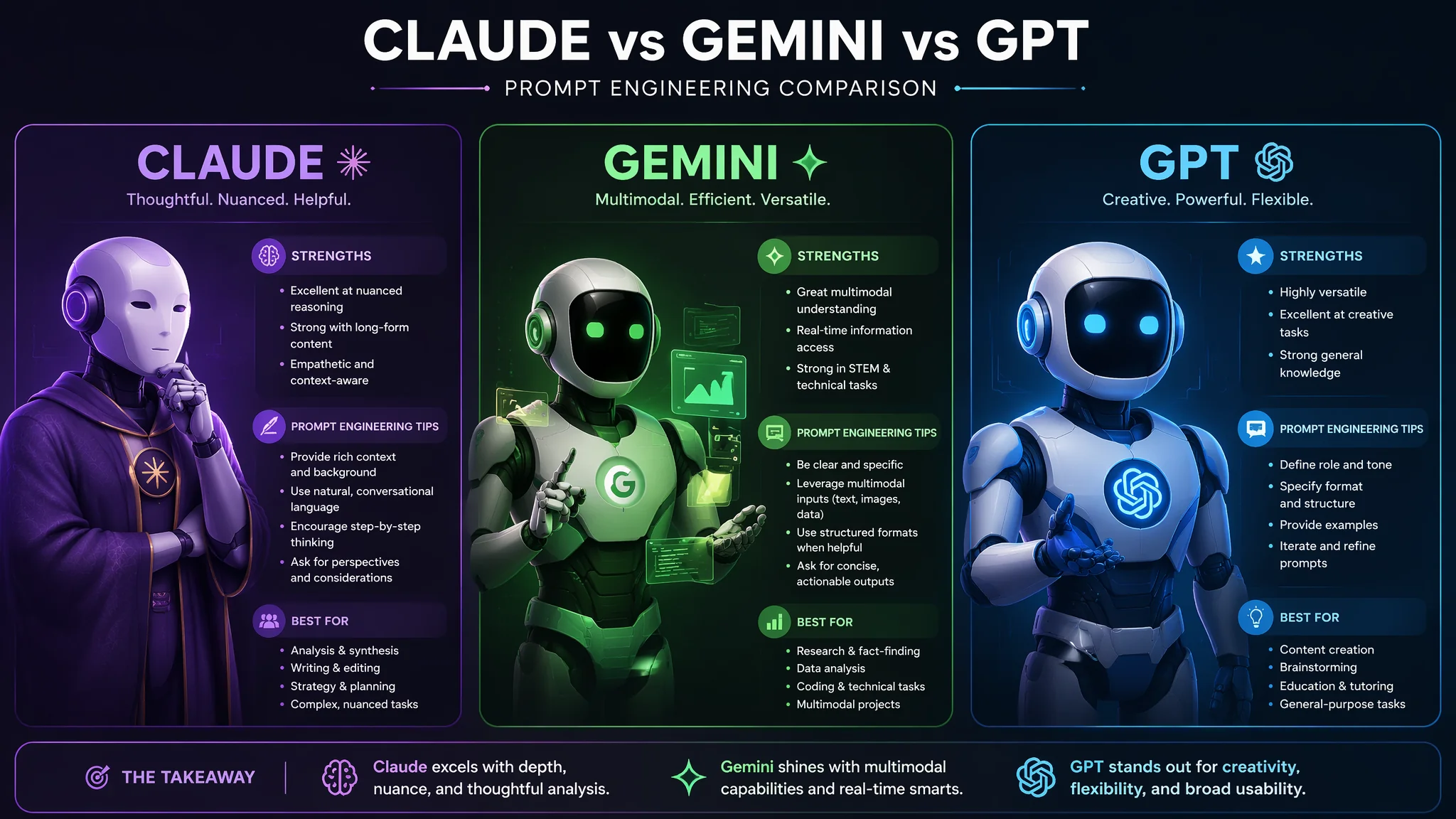
简单说:别把GPT的提示词直接复制给Claude或Gemini——三个模型的"审美"完全不一样。Claude喜欢越多细节越好,Gemini吃结构化格式,GPT则是最随和的那个。搞清楚这些差异,一条提示词能同时适配三个模型。
之前写了一整套Claude提示词给团队用,效果贼好——前提是一直用Claude。换到Gemini上试了一下,同样的提示词,输出直接变成了另一种画风。那一刻我才意识到自己犯了多蠢的错误:我把所有模型当成"同一台机器",以为换个API Key就能无缝切换。
先看一张总览表:三大模型的"性格"差异
写提示词就像跟不同性格的人说话——对直男你不能绕弯子,对细节控你不能只说个大概。三个模型的底层偏好完全不同:
| 特性 | GPT-4o | Claude 4 Sonnet | Gemini 2.5 Pro |
|---|---|---|---|
| 最佳提示词长度 | 100-300 token | 200-600 token | 150-400 token |
| 喜欢的格式 | 自然语言 + markdown | XML标签 + 自然语言 | 结构化指令 + 表格 |
| 角色扮演 | 灵活,创意强 | 稳定,一致性好 | 中等,适合功能性角色 |
| 对上下文细节的需求 | 中等 | 极高——不给就乱猜 | 中等偏高 |
| 负面指令执行度 | 80% | 90% | 60%——常常无视 |
| 长文本生成质量 | 前500字好,后面掉 | 从头到尾稳定 | 波动较大 |
| 结构化输出(JSON等) | 一般 | 优秀 | 优秀 |
| 创意/脑洞能力 | 最强 | 偏保守 | 中等 |
这些不是随便写的——FlowPix内部用同一套20个测试案例跑了三轮对比,上面每一条都是数据支撑的结论。
Claude提示词的独门心法
Claude最大的特点是:你给的信息越多,它输出越好。GPT会在你指令模糊时自己脑补,Claude不会。
什么意思?如果你让GPT"写一个AI工具评测",GPT会自己决定评测什么工具、用哪些维度、写成什么风格。Claude呢?它会写,但会问你一堆澄清问题,或者更糟——用一个你可能完全不认可的方向开始瞎写。
所以给Claude写提示词有一个黄金法则:把"你以为AI应该知道的"全部写出来。你的业务背景、目标用户的画像、之前踩过的坑、甚至你老板的个人偏好——Claude吃得越多,产出越精准。
另外Claude对XML标签的解析能力远强于GPT。Anthropic官方的提示词推荐写法就是用XML包裹不同模块:
<context> 这是一家面向中小企业的SaaS公司... </context> <task> 写一封针对流失客户的挽回邮件 </task> <constraints> - 语气诚恳但不卑微 - 不超过200字 - 必须包含一个具体的优惠数字 </constraints> <example> (这里放一个例子) </example>
这种写法在Claude上好用到离谱,但在GPT上没必要这么正式——自然语言描述就够了。根据Anthropic官方文档,XML标签能提升Claude的指令理解准确率约15-20%。
Gemini提示词:跟前面两个完全不同
Gemini的一个诡异特性:它对"不要做XXX"这种负面指令的执行力远低于GPT和Claude。不夸张地说,你告诉Gemini"不要用第一人称",它大概有一半的概率继续用"我"。
解决方案:把负面指令转成正面指令。比如:
❌ "不要用第一人称" → ✅ "全程使用第三人称写"
❌ "不要使用过于专业的术语" → ✅ "用初中生能读懂的语言解释"
❌ "回答不要超过100字" → ✅ "将回答控制在100字以内"
这个差异不是模型缺陷,是Gemini的训练数据和RLHF策略跟另外两家不同。Google更强调"去做"而非"别做"。
Gemini的另一个强项:多模态提示词。如果你需要让AI同时理解图片+文字+表格,Gemini在这个场景下的表现明显优于Claude(GPT和Gemini不相上下)。原因很简单——Google有YouTube和Google Images的数据优势。
还有一个小发现:Gemini对示例(few-shot)的敏感度比另外两个模型都高。2-3个高质量示例能让Gemini的输出质量飞跃一个档次,而GPT可能只需要1个示例就够了。这跟Google官方提示词策略里的建议一致。
跨模型提示词迁移速查表
如果你的提示词已经在一个模型上跑稳定了,想迁移到另一个模型——用这个表做checklist:
| 从...迁移到... | GPT → Claude | GPT → Gemini | Claude → Gemini |
|---|---|---|---|
| 增加上下文细节 | ✅ 必须 | 建议 | 适当减少 |
| 添加XML/结构化标签 | ✅ 推荐 | 可选 | ✅ 推荐 |
| 添加Few-shot示例 | 建议 | ✅ 必须 | ✅ 必须 |
| 负面指令转正面 | 不需要 | ✅ 必须 | ✅ 必须 |
| 添加输出格式约束 | 建议 | ✅ 必须 | 保持即可 |
最省事的做法:把提示词写成三个版本。看起来工作量大,实际上每个版本只需要改10-20%的内容——格式和语气调整为主,核心逻辑是共通的。
常见问题
能把给GPT写的提示词直接复制给Claude用吗?
大部分情况可以,但效果会打折。Claude对上下文更敏感——GPT能自己脑补的信息,Claude需要你明确说出来。反过来,Claude在用XML标签结构化提示词方面比GPT强得多,这是GPT提示词里基本不需要考虑的事情。
三个模型里谁最适合角色扮演类的提示词?
Claude在角色一致性方面最强,尤其是长篇角色扮演场景。GPT在创意型角色中更灵活。Gemini适合功能性角色(客服、技术支持)——它的结构化输出更稳定。
Gemini提示词有什么特别的写法吗?
Gemini最吃结构化。用明确的"输入:""输出:"格式标注、配合markdown表格做示例,效果比写长篇散文式提示词好得多。另外Gemini对负面指令("不要做XXX")的执行力比Claude和GPT都弱——最好用正面指令替代。
说到底,每条提示词都应该标注"适用于哪个模型"。现在跨模型迁移已经成了日常操作,硬套只会让自己多花冤枉的调试时间。觉得有用的话转发给你们的AI运维同事吧。