AI配音模型怎么训练?用自己声音训练专属配音模型的方法
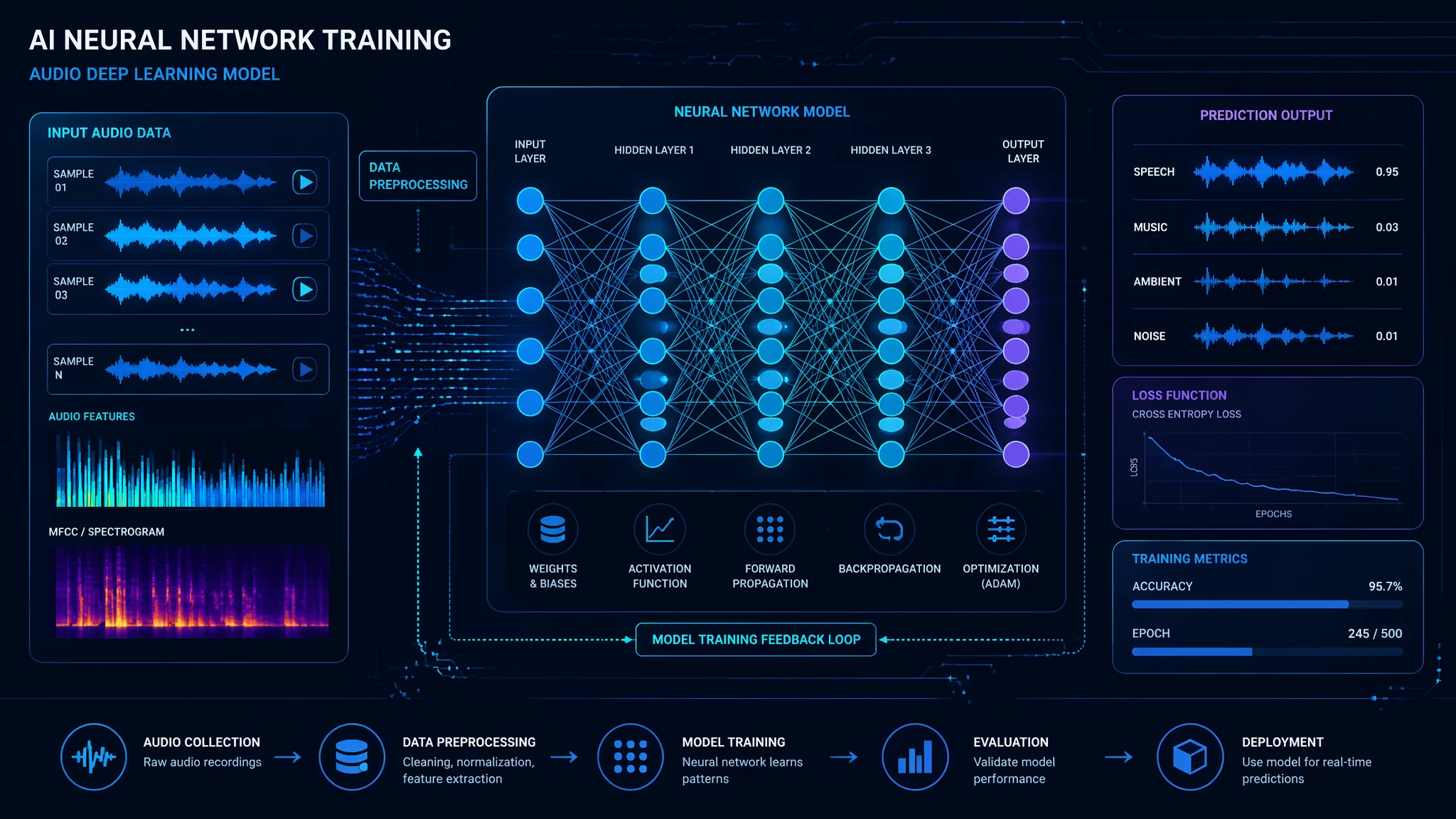
简单说:训练自己的AI配音模型,最少8分钟音频就能起步,但要做到九分像需要30到60分钟高质量素材。五步流程是采集、清洗、标注、训练、测试。手机能录但建议用USB电容麦,300块的就够。录的时候情绪和语速要有变化,全用单调的语气读模型会很呆。
AI配音模型怎么训练?用自己声音训练专属配音模型的方法
去年我自己训了一个声音模型,前后搞了三版才满意。第一版用手机录了15分钟素材,训出来的声音像我又不太像我——我老婆听了说"这是你感冒时候的声音吧"。第二版换了麦克风但读的都是新闻稿,模型太端着了。第三版终于摸清门路,现在做视频再也不用自己录旁白了。
第一步:数据采集——录什么、录多久、怎么录
先说一个容易被忽略的真相:录音质量 > 录音数量。我见过有人录了三个小时的素材,但全程用手机放在一米外录的,房间还有回音,训出来的模型全是糊的。相反有人只录了20分钟,但用的是电容麦在吸音房里录的,效果碾压前者。
我的建议是:最少准备30分钟的净时长素材。分成3类:日常说话(10分钟)、朗读文本(15分钟)、情绪表达(5分钟)。日常说话就是随便聊聊今天吃了什么、看了什么电影,保持你最自然的状态。朗读文本要找不同类型的文字——新闻稿、散文、说明书,各3到5段。情绪表达专门录开心的、生气的、难过的片段,每段30秒左右。
录音环境要求不高但必须做到:关窗关门、远离空调冰箱、不用手机扬声器模式。采样率设成48kHz/24bit,文件存WAV。别用MP3,压缩损失的高频信息会直接体现在模型的音质上。设备方面,知乎上有大量百元级USB麦克风横评可以参考,预算300到500块的Blue Snowball或铁三角AT2020USB入门款完全够用。
第二步到第四步:清洗、标注、训练
清洗就是去噪声、去空白、去口误。用Audacity这类免费工具就行,把每段音频的头尾空白剪掉,明显口误的片段直接删,然后整体跑一遍降噪——强度别超过12分贝,否则会伤到齿音和气声。
清洗完的音频切成20到40秒一段。太长模型学不细,太短缺上下文。我一般切25秒左右,30分钟的素材大概能切出70到80个片段。
标注这一步最枯燥但也最关键。要把每个片段对应的文字内容写出来,每行一个字幕文件。格式建议用TXT或CSV,一行文件名对应一行文本。不要省略任何语气词——你说了"嗯""啊""这个"都要标上,因为这些都是音色特征的一部分。我之前偷懒跳过了一些口语词,结果模型生成时一到口头禅位置就卡壳。
训练这一步,如果你用的是在线AI配音平台,上传素材等40到90分钟就行,后台自动完成。如果是本地训练(用VITS或FastSpeech2之类的开源框架),单张RTX 3060显卡训30分钟素材大概需要2到3小时。详细的本地部署步骤在FlowPix博客的技术专栏里有保姆级教程。
据巨量引擎的统计,2025年使用AI配音的内容创作者中有37%已经尝试过训练自己的专属声音模型,比2024年翻了一倍。说明这个需求不是小众玩法了。
第五步:测试和迭代——怎么判断模型训好了
训完别急着用。先拿5段你从来没录过的文本跑一遍生成,然后做AB盲测:把原声和AI生成的声音混在一起,找3个熟悉你声音的人判断哪个是真人。如果3个人里有2个以上分不清,说明模型过关了。我第三版模型就是这个标准通过的。
如果效果不理想,通常是这几个原因:录音素材的音量不一致——有些段声音大有些小,模型会学到一个"忽大忽小"的特征;或者是语速太单一,全是中速读新闻,模型没法处理快语速和慢语速。回炉的方法是补录10到15分钟针对性的素材,比如如果模型快语速不行就专门录一批语速快的、慢语速同理。
模型训好之后的使用场景太多了。做视频博主的话,写稿直接生成配音,不用每次架麦录音。做跨境配音的可以把自己的声音克隆成多种语言。甚至可以把模型分享给团队,一人录音全员共享音色——这个功能在FlowPix的声音克隆模块里有个"团队声音库"直接支持。
音色克隆和个性化配音,别搞混了
很多人以为训模型就是音色克隆——完全复制一个人的声音特征。其实还有一个方向叫个性化配音,是指在某个通用模型的基础上"加一点点你的味道",而不是完全变成你。
音色克隆需要大量的素材,30分钟起步,追求的是"听不出是AI"。个性化配音只需要5到8分钟素材,追求的是"音色有你影子但发音更标准"。比如你普通话不太标准但音色好听,就可以做个性化配音——保留你音色的温暖度,但纠掉口音和吐字问题。
选哪个方向取决于你的需求。做播客和有声书建议走全克隆路线,投入大但一劳永逸。做短视频口播走个性化路线就够了,训练快、迭代也快。这两种方案在全AI配音生产线里都有对应的自动化配置,5分钟搞定。
常见问题
训练一个自己的AI配音模型最少需要多少音频数据?
最少需要8到12分钟的清晰人声素材,但效果只能做到六七分像。要达到九分以上的还原度,建议准备30到60分钟的高质量录音。录音要涵盖不同情绪状态(平静、开心、严肃)和不同语速(慢、中、快),每段20到40秒,总共大概80到150个片段。用单一句式反复录是没用的,AI需要多样性才能学到音色的本质特征。
用手机录音能训练AI配音模型吗?还是一定要用专业麦克风?
手机录音可以用,但效果会打折扣。手机麦克风在200Hz以下和6kHz以上的频率响应衰减严重,训练出来的模型声音会偏"薄"和偏"闷"。如果暂时没有专业设备,至少做到三点:在安静密闭的房间录、距离嘴巴15到20厘米、用WAV格式而非MP3。有条件的买个USB电容麦,300到500块的入门款就够用。
训练完成后生成的配音能用于商业用途吗?
用自己录制的声音训练的模型,生成的配音版权归你所有,可以自由商用。但如果你是用别人的声音数据训练的(比如从网上扒下来的名人音频),生成的配音用于商业用途存在侵权风险。建议只用自己的声音或者获得了明确授权的音频素材进行训练,商业使用前看清楚你所用AI平台的用户协议条款。
觉得有用的话分享给朋友吧。