AI语音配音与字幕匹配怎么做?4种方案让音画字幕完美同步
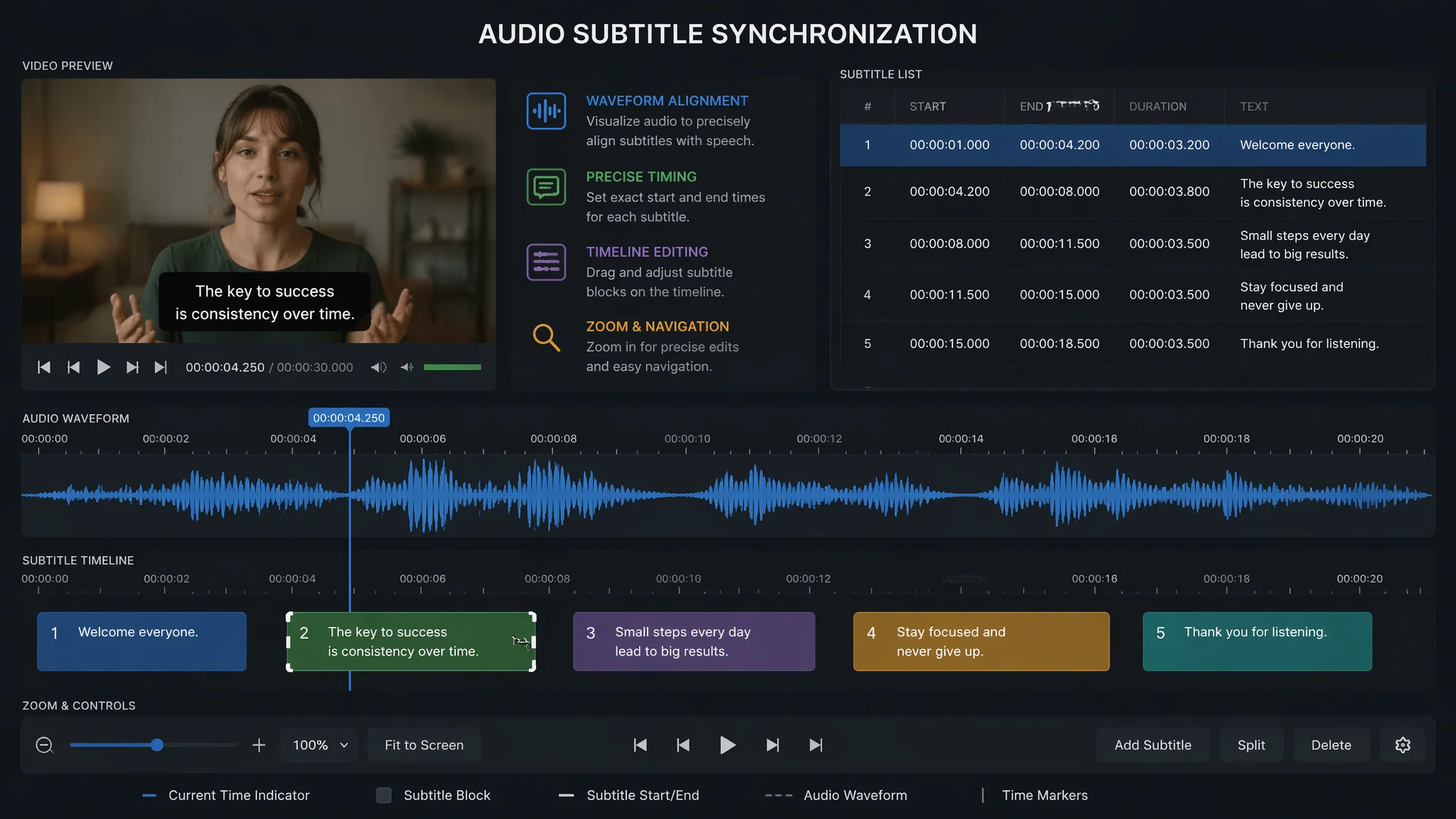
简单说:AI配音和字幕匹配的核心是让音频、画面、字幕三者的时间轴对齐。可以用剪映的自动字幕功能,也可以用SRT文件手动导入。这篇把从自动识别到手动微调的方法都讲清楚。
AI语音配音与字幕匹配:4种方案让三者完美同步
做过视频的人都知道一个头疼的事:AI配音做好了,字幕却对不上。要么字幕出来早了半秒,要么某句话的结尾字幕还没消失,下一句已经开始了。
观众对字幕的敏感度比你想的高。字幕和配音哪怕差0.3秒,看着就会觉得"这个视频做得不专业"。所以配音和字幕的匹配这件事,值得花点时间搞明白。
我试了几种不同的方案,从全自动到半手动都有,下面按操作难度从低到高排列。
方案一:剪映自动识别字幕(最省事)
剪映的"智能字幕"功能可以直接对AI配音音频做语音识别,自动生成字幕。
操作步骤:
- 在剪映中导入你的AI配音音频(已经放到时间线上的那种)
- 点击"文本"→"智能字幕"→"识别字幕"
- 选择语言(中文/英文/自动识别)
- 等待识别完成,通常1分钟的视频大概需要15-20秒处理
- 检查生成的字幕,逐条微调不准确的地方
这个方案的好处是快。坏处嘛,识别准确率大概在90-95%之间。一些专业术语、方言词汇容易识别错,需要你手动改。还有一个问题:如果AI配音的语速比较快,自动字幕的分句可能不太合理——一句话被拆成好几段,或者两段话被合在一起。
更多关于剪映AI配音的操作,之前写过一篇剪映AI配音入门指南可以参考。
方案二:先写文案 → AI配音 → 导入SRT字幕
这个方案的核心是"文案先行"——你先写好完整的文案,用它同时生成AI配音和SRT字幕文件。
为什么这样做更好?因为文案是你的"源头",配音和字幕都从同一份文案来,就不会出现文案版本不一致的问题。
具体流程:
- 把文案按"每句一行"的格式整理好
- 用AI配音工具(比如Azure TTS或魔音工坊)生成音频
- 用字幕编辑工具(比如Subtitle Edit或Arctime)创建SRT文件
- 播放音频,在听到每句话的开始和结束时打时间戳
- 把对应的文案填入每条字幕
- 导出SRT文件,导入剪映
这个方案前期花的时间多一些,但字幕精度很高。特别适合做长视频(5分钟以上),因为长视频的自动字幕一旦出错,手动改的工作量比重新打时间轴还大。
关于AI配音和视频画面的匹配问题,之前也写过一篇AI配音和视频匹配技巧,可以一起看看。
方案三:Python脚本自动生成时间轴字幕
如果你用Azure TTS或者类似的API做配音,可以在生成音频的同时拿到每个词的时间戳信息,然后用脚本自动生成SRT文件。
Azure TTS的Viseme(口型同步)API会返回每个音素的时间点,你可以利用这些数据来拆分字幕。简单的Python代码大概是这样:
把文案按标点分成短句,对每句调用TTS API生成音频并获取时长,然后按累加的方式计算每句话的起止时间,最后拼成SRT格式输出。
这个方案适合批量生产内容的情况。比如你每周要出5条以上的视频,每条视频的文案长度差不多,那写一个脚本可以反复用。虽然第一次调通需要花时间,但后面每次只要换文案就行。
关于AI配音的导出和时间轴控制,AI配音文件下载指南和AI配音时间轴调整这两篇里有更详细的讲解。
方案四:Arctime手动打轴(精度最高)
Arctime是一款免费的字幕编辑软件,专门用来给视频/音频打字幕时间轴。很多字幕组都在用它,精度可以到毫秒级别。
网址:arctime.org
使用方法:
- 下载安装Arctime(Windows/Mac都支持)
- 导入你的AI配音音频文件
- 在顶部文本框输入第一句字幕内容
- 播放音频,在听到这句话开始时按"Enter"打入点
- 在听到这句话结束时再按"Enter"打出点
- 输入下一句,重复以上步骤
- 全部打完后导出为SRT或ASS格式
Arctime的好处是可以精确控制每个字幕的显示和消失时间。而且它支持"拍打模式"——你一边听音频一边按空格键打节拍,软件自动在节拍位置生成时间轴。打10分钟音频的字幕大概30分钟就能搞定,比想象中快。
对于追求字幕效果(字体、颜色、动画)的创作者,导出ASS格式后还可以在Aegisub里进一步编辑样式。
字幕和配音匹配的常见坑
说几个我踩过的坑,帮你少走弯路:
坑1:文案版本不一致。配音用了一版文案,字幕用了另一版。哪怕改了几个字,时间轴就可能对不上。解决办法:所有流程都用同一份文案,改了就同步更新。
坑2:语速变化导致字幕堆叠。AI配音在某段话里语速突然加快(比如读一长串数字),字幕还按正常节奏显示,就会出现字幕堆叠或延迟。解决办法:在语速变化的地方手动调整字幕时长。
坑3:字幕太长一行放不下。超过15个中文字就得考虑换行了。单行字幕建议控制在12-15个字之间,太长观众看不完。
坑4:背景音乐盖住配音。字幕显示的内容跟配音一致,但观众因为背景音乐太大听不清配音,就觉得"字幕跟声音对不上"。解决办法:配音部分的背景音乐音量压到主音量的15-20%。
四种方案对比
| 方案 | 操作难度 | 精度 | 适合场景 | 耗时 |
|---|---|---|---|---|
| 剪映自动识别 | 低 | 90-95% | 短视频(3分钟内) | 5分钟 |
| 文案+SRT导入 | 中 | 98%+ | 中长视频(5分钟+) | 30-60分钟 |
| Python脚本生成 | 高(首次) | 99%+ | 批量生产 | 首次2小时,后续5分钟 |
| Arctime打轴 | 中 | 99.9% | 追求精确 | 音频时长的2-3倍 |
我的建议是:日常短视频用剪映自动识别就行,认真做中长内容用SRT导入,批量产出写脚本,追求完美用Arctime。
做短视频AI配音的完整流程,可以参考短视频AI配音全流程教程。
常见问题
剪映识别字幕的准确率怎么样?
普通话配音的识别准确率大概在92-95%,已经算不错了。主要出错的地方是专有名词(品牌名、人名)和轻声、儿化音。识别完后花2-3分钟过一遍,改掉错误就行。
字幕要加在画面的什么位置?
一般放在画面底部居中,距离底边大约10%的位置。不要贴着底边,也不要太高挡住画面主体。如果视频底部有平台的水印或互动按钮区域(比如抖音),字幕要往上挪一些避开。
英文字幕和中文字幕能同时显示吗?
可以。在剪映里添加两个字幕轨道,中文放下面一行,英文放上面一行。SRT格式不支持双行字幕,需要用ASS格式来做双语字幕。关于多语言配音,可以看看多语言AI配音教程。
字幕这件事看着小,但对视频观感影响很大。把这篇分享给一起剪视频的朋友,大家一起提高视频质量。