开源大模型本地部署教程:2026年在家跑Llama 4和DeepSeek全流程
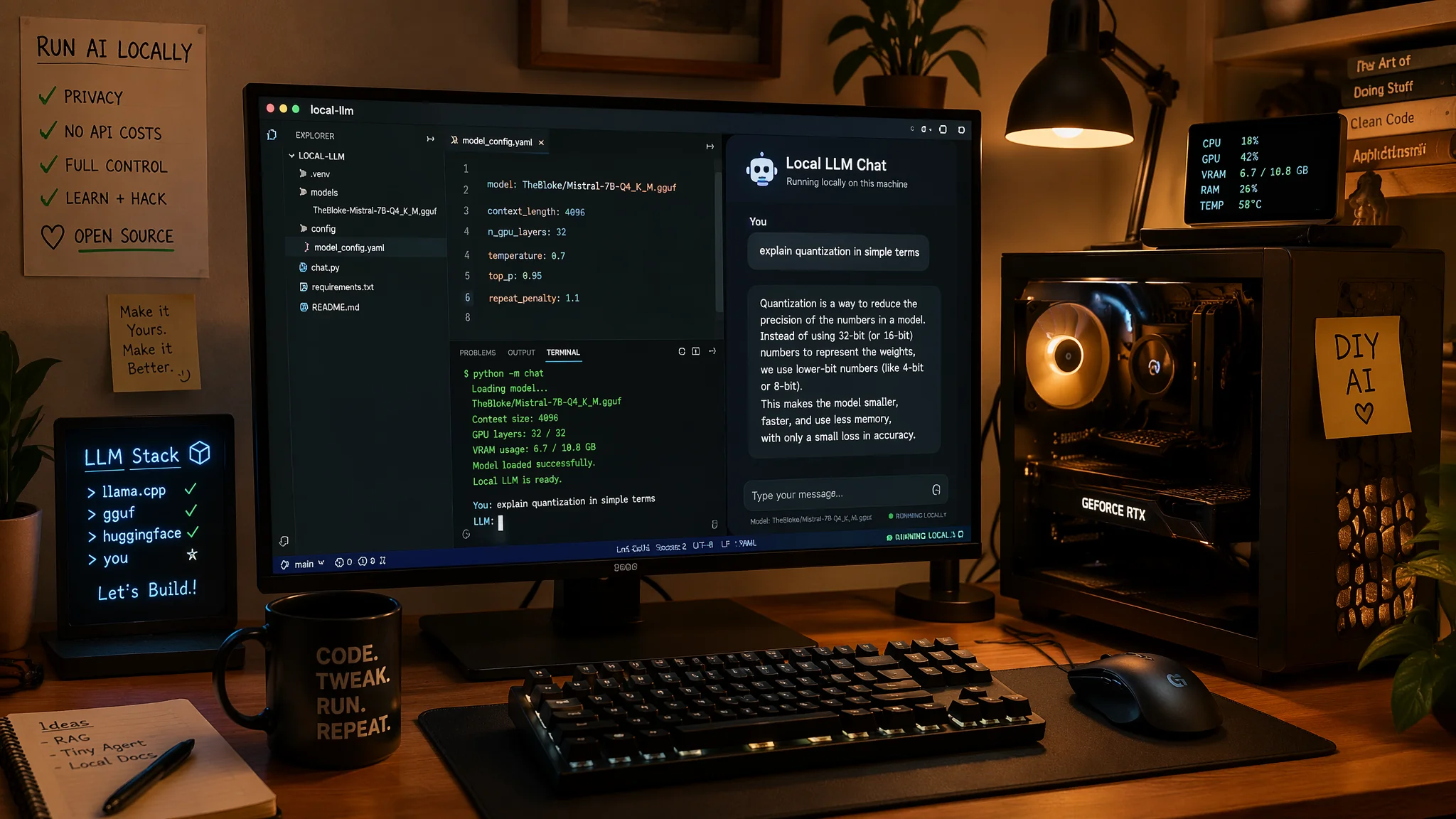
简单说:2026年在自己电脑上跑大模型已经是件门槛很低的事了——一台RTX 4060能流畅跑7B模型,MacBook也能用。这篇教程从零带你装上Ollama或LM Studio,下载模型,一行命令跑起来。
开源大模型本地部署教程:2026年在家跑Llama 4和DeepSeek全流程
ChatGPT Plus一个月20美元,说实话不算贵。但每次把工作文档、代码草稿、私人对话全扔给OpenAI的服务器,心里总有点膈应。2025年有个朋友的公司因为员工用ChatGPT处理了内部合同被信息安全部门警告,从此我对本地大模型这件事认真起来了。
花了一个周末把开源大模型部署到自己的游戏本上,效果比预期好很多。这篇教程记录我的完整流程,包括踩过的坑——希望你少走弯路。
第一步:先搞清楚你要什么
部署前先想清楚三个问题:你要用模型做什么(写代码/翻译/聊天/隐私数据处理)、你的硬件配置、你的技术舒适度。不同的答案导向完全不同的方案。
| 使用场景 | 推荐模型 | 最低配置 | 部署工具 |
|---|---|---|---|
| 日常聊天/写作 | Llama 4-7B | 16GB RAM+8GB显存 | LM Studio |
| 写代码/数学 | DeepSeek Coder V3 | 32GB RAM+16GB显存 | Ollama |
| 中文优化 | Qwen 3-7B | 16GB RAM+8GB显存 | Ollama |
| 隐私数据处理 | Llama 4-13B | 32GB RAM+16GB显存 | Ollama+Docker |
方案A:LM Studio — 零命令行三分钟上手
LM Studio是目前最简单的大模型本地部署方案——图形界面、内置模型下载、一键启动、自带聊天窗口。适合不想碰命令行的用户。
安装流程:LM Studio官网下载 → 安装 → 搜索模型(比如 Llama 4-7B-Instruct)→ 下载 → 点击加载 → 开始聊天。全程不需要输入一行命令。
我装好LM Studio后试的第一个模型是Qwen 3-7B(中文优化),上手体验出乎意料——中文回答流畅度接近GPT-4o mini,响应速度大概每秒15-20个token(4060显卡)。翻译、摘要、闲聊场景完全够用。
LM Studio的局限在于它本质上是个"本地聊天客户端",不像Ollama那样能通过API集成到其他程序里。如果你想在自己的项目里调用本地模型,必须切Ollama。
方案B:Ollama — 开发者首选,API驱动
Ollama是开发者部署本地大模型的首选方案——命令行操作、提供OpenAI兼容API、支持模型自定义。如果你要把本地模型集成到自己的应用里,Ollama是唯一正确的选择。
安装Ollama:去 ollama.com 下载安装包,装完终端里输入 ollama run llama4:7b,模型自动下载 → 启动 → 开始对话。就一行命令。
API调用更简单——Ollama启动后自动在localhost:11434监听,任何支持OpenAI API格式的工具都能对接。比如你在Cursor里把API endpoint改成localhost:11434,就能用本地模型写代码了。这对处理公司代码的人来说是杀手级场景——代码完全不出本机。
我目前的日常使用方案是:隐私敏感的任务用Ollama+本地模型,需要最强能力时切回ChatGPT。两套方案无缝切换,同一套API格式。
硬件避坑指南
显存是本地大模型部署的唯一瓶颈——不是CPU、不是内存、是显存。8GB能跑7B,16GB能跑13B。苹果M系列芯片用统一内存架构,比X86+独显方案对显存要求更低。
自己折腾了两台机器的对比:台式机(RTX 4060 8GB)跑Llama 4-7B速度约15-20 token/s,体验流畅;MacBook Pro M2 Max 32GB跑同样模型用llama.cpp优化版本,速度约22 token/s,反而更快。这是因为苹果的统一内存架构让模型权重直接在GPU和CPU之间共享,少了搬运开销。
想跑13B模型的话,最低配是RTX 4080 16GB或者M2 Max MacBook。70B以上——别想了,家用设备跑不动,得租云GPU(如RunPod一小时几毛钱那种)。
常见问题
本地部署大模型需要什么配置?
7B模型(Llama 4-7B、Qwen 3-7B):16GB内存+RTX 4060 8GB显存即可流畅。13B模型:需32GB内存+RTX 4080 16GB或M2 Max MacBook。70B以上:多卡或云端。纯CPU也能跑但速度慢3-5倍,不推荐作为主力。最低预算方案:一块RTX 3060 12GB二手卡(约1500元)就能跑大部分7B模型。
Ollama和LM Studio哪个好?
Ollama适合开发者——命令行操作、API接口、Docker化部署、可集成到任何应用。LM Studio适合非技术用户——图形界面、一键下载模型、有聊天窗口。如果你只想装个本地ChatGPT替代品,选LM Studio。如果你要把模型集成到项目里或需要API调用,选Ollama。
本地部署的模型和ChatGPT差距大吗?
2026年差距已大幅缩小。Llama 4-7B在推理和摘要上接近GPT-4o mini,DeepSeek V3在数学和代码上甚至与GPT-4不相上下。但创意写作、多轮对话理解等仍有差距。本地模型的优势是隐私零泄露、零月费、可定制微调、可离线使用。劣势是能力上限和工具生态不如商业模型。
部署过程中遇到问题了吗?转发给正在折腾本地AI的朋友一起讨论。