卷积神经网络是怎么帮你修图的?用大白话讲清楚CNN
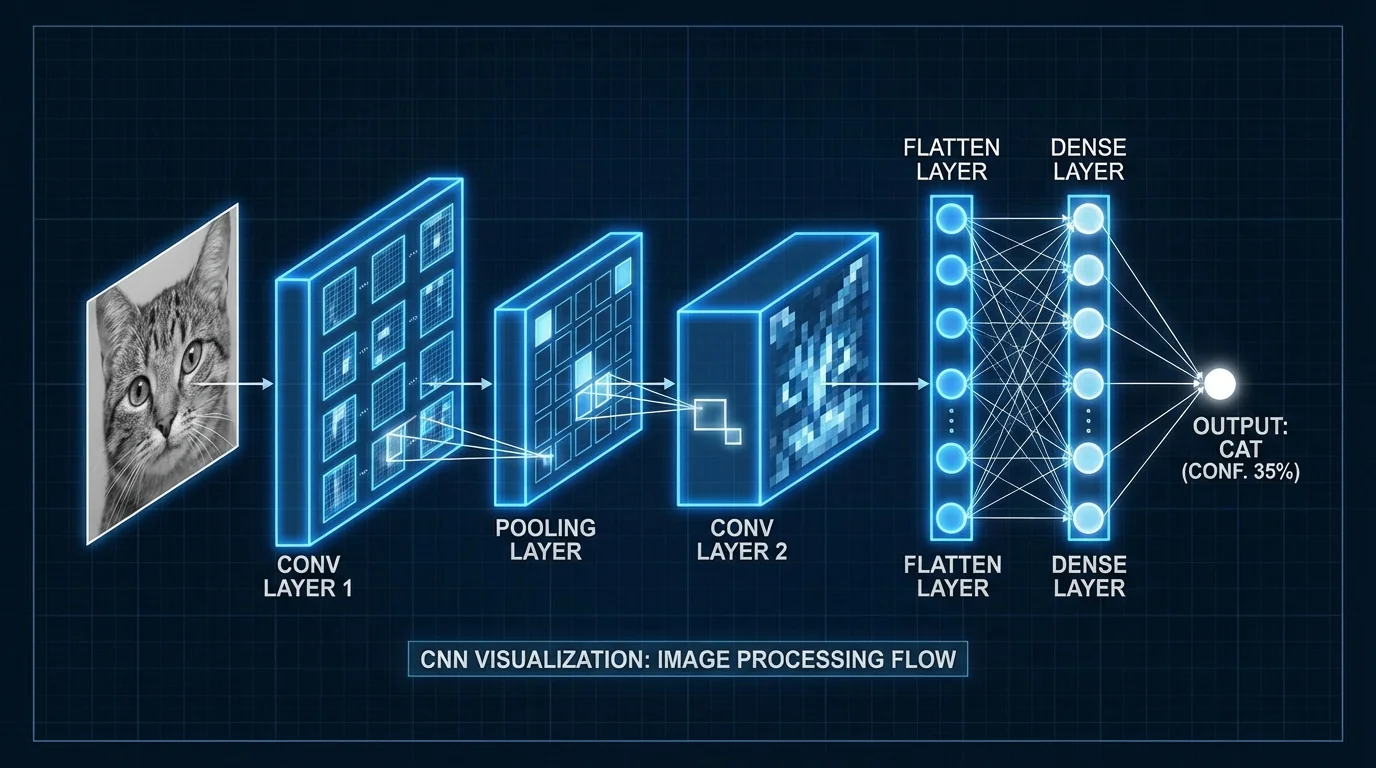
简单说:CNN(卷积神经网络)是AI修图里负责"看"的那部分——识别人脸、抠图、找边缘。它用一个个小滤镜扫过图片,一层层提取特征,最后告诉你"这是眼睛""那是背景"。修图软件里的一键抠图、智能选择主体,背后都是CNN在干活。
你点一下"选择主体",软件秒把人抠出来。背后是什么?
FlowPix编辑部查了资料,用人话讲清楚。卷积神经网络(CNN)听起来高大上,其实原理不难懂。
卷积是什么?小滤镜扫图
卷积就是拿一个小方块(叫卷积核或滤波器)在图片上从左到右、从上到下慢慢滑动,每停一步算一个数。就像用放大镜一寸一寸看照片,把局部特征"提取"出来。
比如一个 3×3 的卷积核专门检测"边缘"——竖线、横线、斜线。扫完一整张图,输出一张"边缘图"。再换一个卷积核,可能专门找"皮肤纹理"。层层叠叠,浅层抓边缘、颜色,深层抓眼睛、鼻子、整张脸。
根据arXiv上图像识别相关论文统计,2024年CNN在图像分割任务上的准确率已超95%。修图软件能秒抠图,就是因为CNN把"人"和"背景"分得清清楚楚。
CNN在修图里具体干什么
抠图、人脸检测、选择主体、去背景——这些"识别类"功能,基本都是CNN干的。它不负责"生成"新像素,只负责"看懂"图里有什么、在哪。
你点"选择主体",CNN扫一遍图,输出一个 mask:人物区域标1,背景标0。后面的算法根据这个 mask 做抠图、换背景。瘦脸、大眼也一样——先要CNN标出眼睛位置、脸型轮廓,变形算法才能动。
上周我试了某款修图App的一键抠图,头发丝都能抠干净。背后就是CNN+分割模型。U-Net、DeepLab、MODNet 这些架构,都是CNN的变种。Wikipedia上有CNN的完整定义。修图软件底层用的就是这类网络。
和GAN、扩散模型有啥区别
CNN负责"看",GAN和扩散模型负责"造"。CNN识别、分割;GAN和扩散模型生成、补全、增强。分工不同。
老照片修复、模糊变清晰、智能填充——这些要"造"出新像素,用的是GAN或扩散模型。CNN不干这个,它只告诉你"这里缺了一块""这是人脸"。想了解完整技术栈,看神经网络如何修图;算法原理看AI修图算法揭秘。
FlowPix编辑部结论:卷积AI修图不是玄学,是数学。CNN把图"看懂",别的模型再动手修。理解个大概,用起来心里有数。想玩深度学习修图,可以看深度学习修图还原技术;主流模型盘点看主流AI修图模型。
常见问题
什么是卷积神经网络是帮你修图的用大白话讲清楚C?
,涉及相关技术和应用场景的快速发展。
AI在?
目前在短视频制作、内容创作、效率工具等领域已有不少实际落地的应用案例,能帮用户节省大量时间和精力。
卷积神经网络是帮你修图的用大白话讲清楚C和传统方法比有什么优势?
相比传统方法,AI方案在速度、成本和可扩展性上有明显优势,但精细度和创意方面仍需人工把关。